Tutorial (Structured Data Processing)
Contents
Tutorial (Structured Data Processing)#
(Last updated: Sep 8, 2025)1
This tutorial will familiarize you with the data science pipeline of processing structured data, using a real-world example of building models to predict and explain the presence of bad smell events in Pittsburgh based on air quality and weather data. The models are used to send push notifications about bad smell events to inform citizens, as well as to explain local pollution patterns to inform stakeholders.
The scenario is in the next section of this tutorial, and more details are in the introduction section of the Smell Pittsburgh paper. We will use the same dataset as used in the Smell Pittsburgh paper as an example of structured data. During this tutorial, we will explain what the variables in the dataset mean and also guide you through model building. Below is the pipeline of this tutorial.
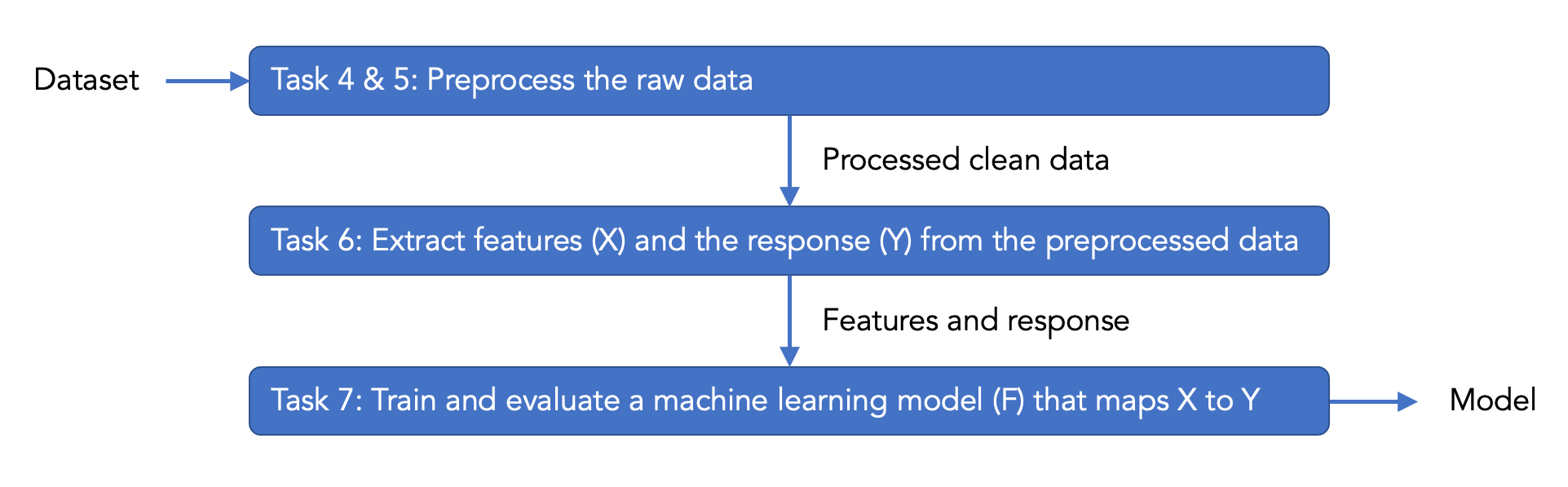
You can use the following link to jump to the tasks and assignments:
Scenario#
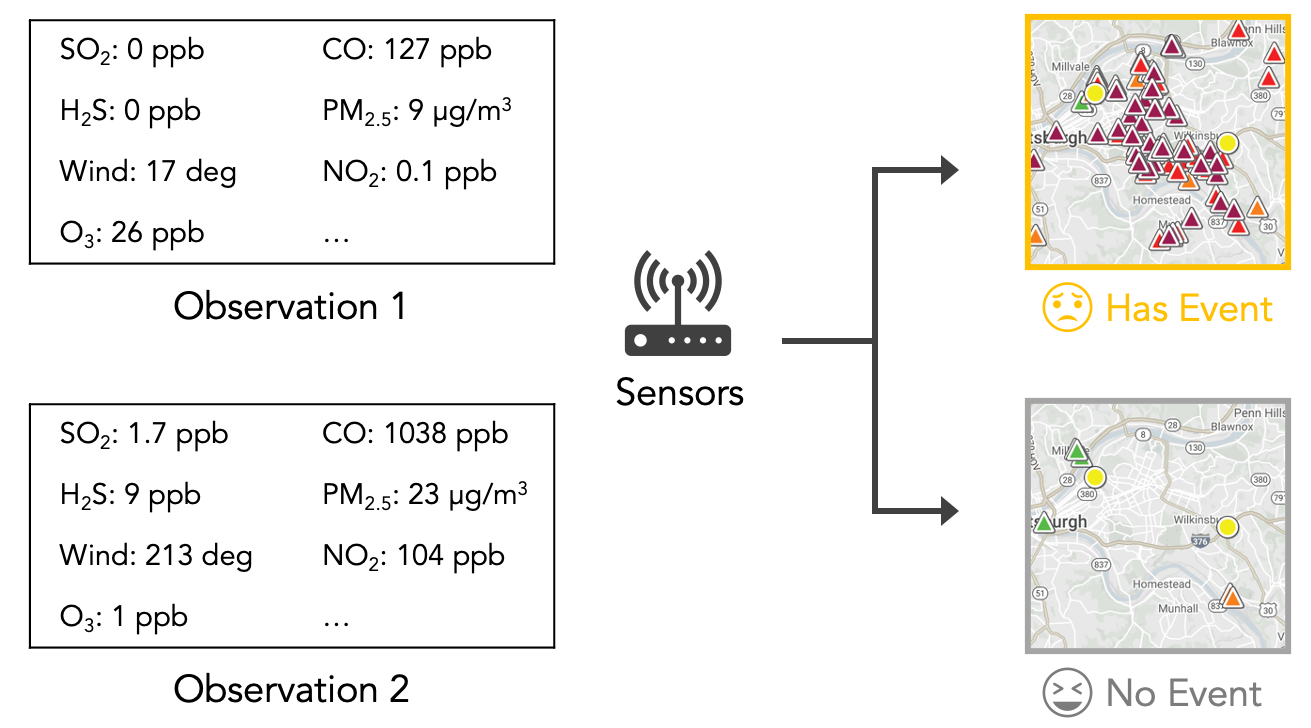
Local citizens in Pittsburgh are organizing communities to advocate for changes in air pollution regulations. Their goal is to investigate the air pollution patterns in the city to understand the potential sources related to the bad odor. The communities rely on the Smell Pittsburgh application (as indicated in the figure below) to collect smell reports from citizens that live in the Pittsburgh region. Also, there are air quality and weather monitoring stations in the Pittsburgh city region that provide sensor measurements, including common air pollutants and wind information.
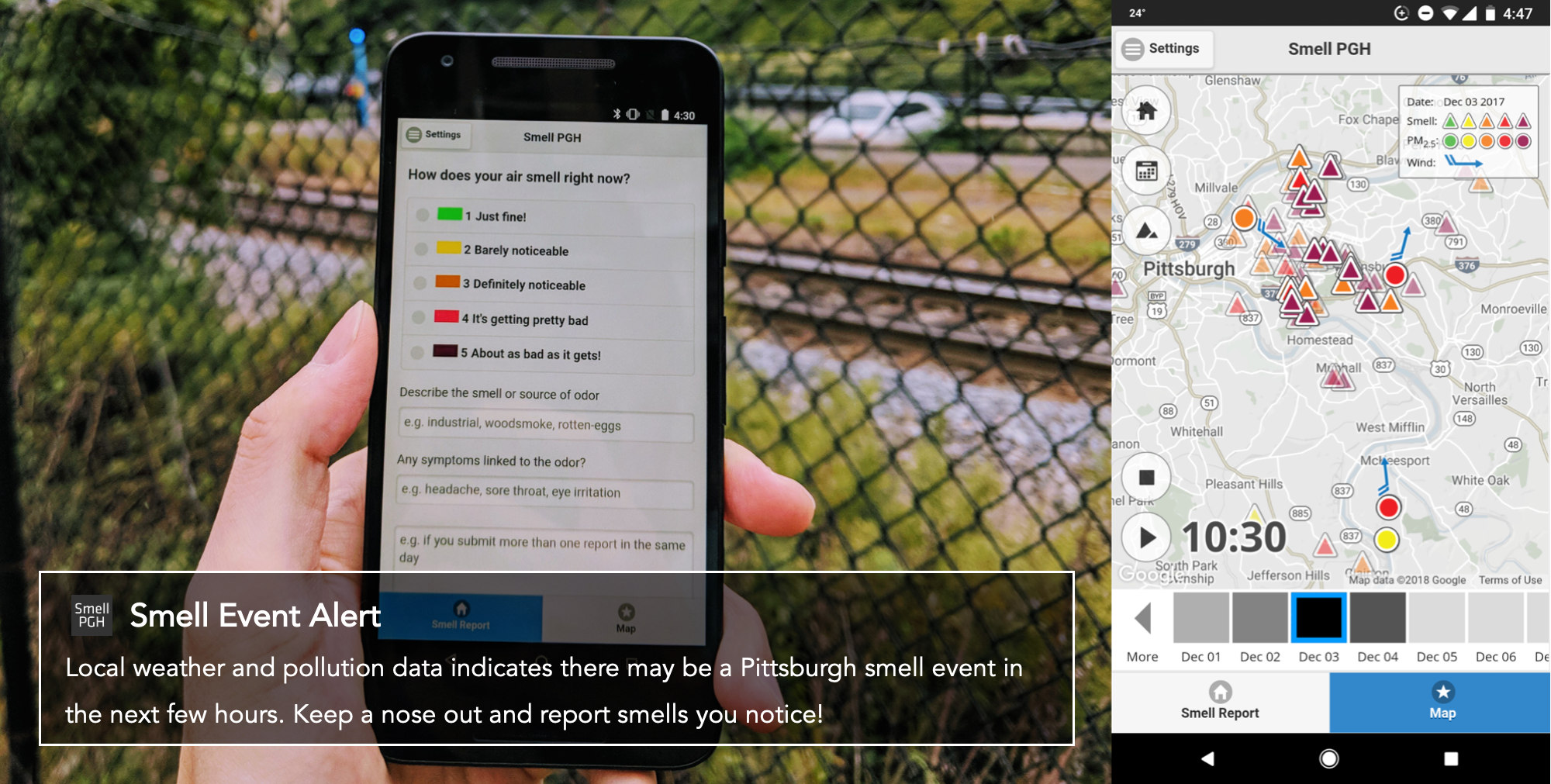
You work in a data science team to develop models to map the sensor data to bad smell events. Your team has been working with the Pittsburgh local citizens closely for a long time, and therefore you know the meaning of each variable in the feature set that is used to train the machine learning model. The Pittsburgh community needs your help timely to analyze the data that can help them present evidence of air pollution to the municipality and explain the patterns to the general public.
Import Packages#
Important
You need to install the packages in this link in your Python development environment.
We put all the packages that are needed for this tutorial below:
Set the global style of all Pandas table output:
import pandas as pd
import numpy as np
import seaborn as sns
from os.path import isfile, join
from os import listdir
from sklearn.dummy import DummyClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import plotly.express as px
# Import the answers for the tasks
from util.answer import (
answer_preprocess_sensor,
answer_preprocess_smell,
answer_sum_current_and_future_data,
answer_experiment
)
# Import the utility functions that are provided
from util.util import (
check_answer_df,
compute_feature_importance,
train_and_evaluate,
plot_smell_by_day_and_hour,
convert_wind_direction,
insert_previous_data_to_cols,
get_pca_result
)
from IPython.core.display import HTML
def set_global_df_style():
styles = """
<style>
.dataframe * {font-size: 1em !important;}
</style>
"""
return HTML(styles)
# Call this function in a notebook cell to apply the style globally
set_global_df_style()
Task Answers#
Click on one of the following links to check answers for the assignments in this tutorial. Do not check the answers before practicing the tasks.
Click this for task answers if you open this notebook on your local machine
Click this for task answers if you view this notebook on a web browser
Utility File#
Click on one of the following links to check the provided functions in the utility file for this tutorial.
Click this for utility functions if you open this notebook on your local machine
Click this for utility functions if you view this notebook on a web browser
Task 4: Preprocess Sensor Data#
In this task, we will process the sensor data from various air quality monitoring stations in Pittsburgh. First, we need to load all the sensor data.
path = "smellpgh-v1/esdr_raw"
list_of_files = [f for f in listdir(path) if isfile(join(path, f))]
sensor_raw_list = []
for f in list_of_files:
sensor_raw_list.append(pd.read_csv(join(path, f)).set_index("EpochTime"))
Now, the sensor_raw_list variable contains all the data frames with sensor values from different air quality monitoring stations. Noted that sensor_raw_list is an array of data frames. We can print one of them to take a look, as shown below.
sensor_raw_list[0]
| 3.feed_1.SO2_PPM | 3.feed_1.H2S_PPM | 3.feed_1.SIGTHETA_DEG | 3.feed_1.SONICWD_DEG | 3.feed_1.SONICWS_MPH | |
|---|---|---|---|---|---|
| EpochTime | |||||
| 1477891800 | 0.0 | 0.0 | 51.7 | 343.0 | 3.6 |
| 1477895400 | 0.0 | 0.0 | 52.7 | 351.0 | 3.5 |
| 1477899000 | 0.0 | 0.0 | 52.6 | 359.0 | 3.4 |
| 1477902600 | 0.0 | 0.0 | 48.3 | 5.0 | 2.1 |
| 1477906200 | 0.0 | 0.0 | 31.1 | 41.0 | 2.2 |
| ... | ... | ... | ... | ... | ... |
| 1538267400 | 0.0 | 0.0 | 35.2 | 39.0 | 1.7 |
| 1538271000 | 0.0 | 0.0 | 48.2 | 53.0 | 1.3 |
| 1538274600 | 0.0 | 0.0 | 30.9 | 62.0 | 1.5 |
| 1538278200 | 0.0 | 0.0 | 21.5 | 53.0 | 2.0 |
| 1538281800 | 0.0 | 0.0 | 52.1 | 36.0 | 1.7 |
16729 rows × 5 columns
The EpochTime index is the timestamp in epoch time, which means the number of seconds that have elapsed since January 1st, 1970 (midnight UTC/GMT). Other columns mean the sensor data from an air quality monitoring station.
Next, we need to resample and merge all the sensor data frames so that they can be used for modeling. Our goal is to have a dataframe that looks like the following:
df_sensor = answer_preprocess_sensor(sensor_raw_list)
df_sensor
| 3.feed_1.SO2_PPM | 3.feed_1.H2S_PPM | 3.feed_1.SIGTHETA_DEG | 3.feed_1.SONICWD_DEG | 3.feed_1.SONICWS_MPH | 3.feed_23.CO_PPM | 3.feed_23.PM10_UG_M3 | 3.feed_29.PM10_UG_M3 | 3.feed_29.PM25_UG_M3 | 3.feed_11067.CO_PPB..3.feed_43.CO_PPB | ... | 3.feed_3.SO2_PPM | 3.feed_3.SONICWD_DEG | 3.feed_3.SONICWS_MPH | 3.feed_3.SIGTHETA_DEG | 3.feed_3.PM10B_UG_M3 | 3.feed_5975.PM2_5 | 3.feed_27.NO_PPB | 3.feed_27.NOY_PPB | 3.feed_27.CO_PPB | 3.feed_27.SO2_PPB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EpochTime | |||||||||||||||||||||
| 2016-10-31 06:00:00+00:00 | 0.0 | 0.0 | 51.7 | 343.0 | 3.6 | 0.2 | 7.0 | 8.0 | 8.0 | 159.5 | ... | 0.0 | 344.0 | 2.9 | 43.0 | 9.0 | 0.0 | 0.1 | 2.6 | -1.0 | 0.2 |
| 2016-10-31 07:00:00+00:00 | 0.0 | 0.0 | 52.7 | 351.0 | 3.5 | 0.2 | 8.0 | 8.0 | 8.0 | -1.0 | ... | 0.0 | 330.0 | 2.5 | 43.6 | 13.0 | 5.0 | -1.0 | -1.0 | 106.1 | 0.0 |
| 2016-10-31 08:00:00+00:00 | 0.0 | 0.0 | 52.6 | 359.0 | 3.4 | 0.2 | 5.0 | 7.0 | 7.0 | 133.0 | ... | 0.0 | 0.0 | 3.1 | 40.9 | 7.0 | 9.0 | 0.2 | 2.1 | 105.8 | -1.0 |
| 2016-10-31 09:00:00+00:00 | 0.0 | 0.0 | 48.3 | 5.0 | 2.1 | 0.2 | 3.0 | 4.0 | 4.0 | 236.6 | ... | 0.0 | 325.0 | 1.9 | 40.0 | 11.0 | 3.0 | 0.1 | 3.1 | 111.7 | 0.0 |
| 2016-10-31 10:00:00+00:00 | 0.0 | 0.0 | 31.1 | 41.0 | 2.2 | 0.2 | 5.0 | 5.0 | 4.0 | 269.3 | ... | 0.0 | 347.0 | 1.4 | 45.1 | 10.0 | 9.0 | 0.1 | 2.5 | 127.2 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2018-09-30 01:00:00+00:00 | 0.0 | 0.0 | 35.2 | 39.0 | 1.7 | 0.3 | 20.0 | 15.0 | 10.0 | 455.1 | ... | 0.0 | 39.0 | 1.3 | 57.3 | 11.0 | 5.0 | 0.1 | 12.1 | 301.0 | 0.0 |
| 2018-09-30 02:00:00+00:00 | 0.0 | 0.0 | 48.2 | 53.0 | 1.3 | 0.3 | 25.0 | 19.0 | 12.0 | 761.2 | ... | 0.0 | 70.0 | 1.0 | 54.4 | 21.0 | 7.0 | 0.2 | 13.5 | 357.7 | 0.0 |
| 2018-09-30 03:00:00+00:00 | 0.0 | 0.0 | 30.9 | 62.0 | 1.5 | 0.4 | 23.0 | 55.0 | 33.0 | 1125.4 | ... | 0.0 | 75.0 | 0.7 | 59.5 | 33.0 | 8.0 | 0.6 | 13.8 | 373.6 | 0.0 |
| 2018-09-30 04:00:00+00:00 | 0.0 | 0.0 | 21.5 | 53.0 | 2.0 | 0.5 | 23.0 | 63.0 | 39.0 | 1039.5 | ... | 0.0 | 74.0 | 0.7 | 50.7 | 32.0 | 17.0 | 0.6 | 11.4 | 381.0 | 0.0 |
| 2018-09-30 05:00:00+00:00 | 0.0 | 0.0 | 52.1 | 36.0 | 1.7 | 0.4 | 25.0 | 47.0 | 33.0 | 1636.3 | ... | 0.0 | 65.0 | 0.4 | 77.1 | 27.0 | 18.0 | 2.0 | 13.1 | 377.7 | 0.0 |
16776 rows × 43 columns
In the expected output above, the EpochTime index is converted from timestamps into pandas datetime objects, which has the format year-month-day hour:minute:second+timezone. The +00:00 string means the GMT/UTC timezone. Other columns mean the average value of the sensor data in the previous hour. For example, 2016-10-31 06:00:00+00:00 means October 31 in 2016 at 6AM UTC time, and the cell with column 3.feed_1.SO2_PPM means the averaged SO2 (sulfur dioxide) values from 5:00 to 6:00.
The column name suffix SO2_PPM means sulfur dioxide in unit PPM (parts per million). The prefix 3.feed_1. in the column name means a specific sensor (feed ID 1). You can ignore the 3. at the begining of the column name. You can find the list of sensors, their names with feed ID (which will be in the data frame columns), and also the meaning of all the suffixes from this link.
Some column names look like 3.feed_11067.X..3.feed_43.X. This means that the column has data from two sensor stations (feed ID 11067 and 43). The reason is that some sensor stations are replaced by the new ones over time. So in this case, we merge sensor readings from both feed ID 11067 and 43.
Assignment for Task 4#
Your task (which is your assignment) is to write a function to do the following:
Sensors can report in various frequencies. So, for each data frame, we need to resample the data by computing the hourly average of sensor measurements from the “previous” hour. For example, at time 8:00, we want to know the average of sensor values between 7:00 and 8:00.
Hint: Use the
pandas.to_datetimefunction when converting timestamps to datetime objects. Type?pd.to_datetimein a code cell for more information.Hint: Use the
pandas.DataFrame.resamplefunction to resample data. Type?pd.DataFrame.resamplein a code cell for more information.Hint: Use the
pandas.merge_orderedfunction when merging data frames. Type?pd.merge_orderedin a code cell for more information.
Then, merge all the data frames based on their time stamp, which is the
EpochTimecolumn.Finally, fill in the missing data with the value -1. The reason for not using 0 is that we want the model to know if sensors give values (including zero) or no data.
Hint: Use the
pandas.DataFrame.fillnafunction when treating missing values. Type?pd.DataFrame.fillnain a code cell for more information.
Notice that you need to convert the column types in the dataframe to float to avoid errors when checking if the answers match the desired output. You can use the
pandas.DataFrame.astypefunction to do thisdf = df.astype(float).
def preprocess_sensor(df_list):
"""
Preprocess sensor data.
Parameters
----------
df_list : list of pandas.DataFrame
A list of data frames that contain sensor data from multiple stations.
Returns
-------
pandas.DataFrame
The preprocessed sensor data.
"""
###################################
# Fill in your answer here
return None
###################################
The code below tests if the output of your function matches the expected output.
check_answer_df(preprocess_sensor(sensor_raw_list), df_sensor, n=1)
Test case 1 failed.
Your output is:
None
Expected output is:
3.feed_1.SO2_PPM 3.feed_1.H2S_PPM \
EpochTime
2016-10-31 06:00:00+00:00 0.0 0.0
2016-10-31 07:00:00+00:00 0.0 0.0
2016-10-31 08:00:00+00:00 0.0 0.0
2016-10-31 09:00:00+00:00 0.0 0.0
2016-10-31 10:00:00+00:00 0.0 0.0
... ... ...
2018-09-30 01:00:00+00:00 0.0 0.0
2018-09-30 02:00:00+00:00 0.0 0.0
2018-09-30 03:00:00+00:00 0.0 0.0
2018-09-30 04:00:00+00:00 0.0 0.0
2018-09-30 05:00:00+00:00 0.0 0.0
3.feed_1.SIGTHETA_DEG 3.feed_1.SONICWD_DEG \
EpochTime
2016-10-31 06:00:00+00:00 51.7 343.0
2016-10-31 07:00:00+00:00 52.7 351.0
2016-10-31 08:00:00+00:00 52.6 359.0
2016-10-31 09:00:00+00:00 48.3 5.0
2016-10-31 10:00:00+00:00 31.1 41.0
... ... ...
2018-09-30 01:00:00+00:00 35.2 39.0
2018-09-30 02:00:00+00:00 48.2 53.0
2018-09-30 03:00:00+00:00 30.9 62.0
2018-09-30 04:00:00+00:00 21.5 53.0
2018-09-30 05:00:00+00:00 52.1 36.0
3.feed_1.SONICWS_MPH 3.feed_23.CO_PPM \
EpochTime
2016-10-31 06:00:00+00:00 3.6 0.2
2016-10-31 07:00:00+00:00 3.5 0.2
2016-10-31 08:00:00+00:00 3.4 0.2
2016-10-31 09:00:00+00:00 2.1 0.2
2016-10-31 10:00:00+00:00 2.2 0.2
... ... ...
2018-09-30 01:00:00+00:00 1.7 0.3
2018-09-30 02:00:00+00:00 1.3 0.3
2018-09-30 03:00:00+00:00 1.5 0.4
2018-09-30 04:00:00+00:00 2.0 0.5
2018-09-30 05:00:00+00:00 1.7 0.4
3.feed_23.PM10_UG_M3 3.feed_29.PM10_UG_M3 \
EpochTime
2016-10-31 06:00:00+00:00 7.0 8.0
2016-10-31 07:00:00+00:00 8.0 8.0
2016-10-31 08:00:00+00:00 5.0 7.0
2016-10-31 09:00:00+00:00 3.0 4.0
2016-10-31 10:00:00+00:00 5.0 5.0
... ... ...
2018-09-30 01:00:00+00:00 20.0 15.0
2018-09-30 02:00:00+00:00 25.0 19.0
2018-09-30 03:00:00+00:00 23.0 55.0
2018-09-30 04:00:00+00:00 23.0 63.0
2018-09-30 05:00:00+00:00 25.0 47.0
3.feed_29.PM25_UG_M3 \
EpochTime
2016-10-31 06:00:00+00:00 8.0
2016-10-31 07:00:00+00:00 8.0
2016-10-31 08:00:00+00:00 7.0
2016-10-31 09:00:00+00:00 4.0
2016-10-31 10:00:00+00:00 4.0
... ...
2018-09-30 01:00:00+00:00 10.0
2018-09-30 02:00:00+00:00 12.0
2018-09-30 03:00:00+00:00 33.0
2018-09-30 04:00:00+00:00 39.0
2018-09-30 05:00:00+00:00 33.0
3.feed_11067.CO_PPB..3.feed_43.CO_PPB ... \
EpochTime ...
2016-10-31 06:00:00+00:00 159.5 ...
2016-10-31 07:00:00+00:00 -1.0 ...
2016-10-31 08:00:00+00:00 133.0 ...
2016-10-31 09:00:00+00:00 236.6 ...
2016-10-31 10:00:00+00:00 269.3 ...
... ... ...
2018-09-30 01:00:00+00:00 455.1 ...
2018-09-30 02:00:00+00:00 761.2 ...
2018-09-30 03:00:00+00:00 1125.4 ...
2018-09-30 04:00:00+00:00 1039.5 ...
2018-09-30 05:00:00+00:00 1636.3 ...
3.feed_3.SO2_PPM 3.feed_3.SONICWD_DEG \
EpochTime
2016-10-31 06:00:00+00:00 0.0 344.0
2016-10-31 07:00:00+00:00 0.0 330.0
2016-10-31 08:00:00+00:00 0.0 0.0
2016-10-31 09:00:00+00:00 0.0 325.0
2016-10-31 10:00:00+00:00 0.0 347.0
... ... ...
2018-09-30 01:00:00+00:00 0.0 39.0
2018-09-30 02:00:00+00:00 0.0 70.0
2018-09-30 03:00:00+00:00 0.0 75.0
2018-09-30 04:00:00+00:00 0.0 74.0
2018-09-30 05:00:00+00:00 0.0 65.0
3.feed_3.SONICWS_MPH 3.feed_3.SIGTHETA_DEG \
EpochTime
2016-10-31 06:00:00+00:00 2.9 43.0
2016-10-31 07:00:00+00:00 2.5 43.6
2016-10-31 08:00:00+00:00 3.1 40.9
2016-10-31 09:00:00+00:00 1.9 40.0
2016-10-31 10:00:00+00:00 1.4 45.1
... ... ...
2018-09-30 01:00:00+00:00 1.3 57.3
2018-09-30 02:00:00+00:00 1.0 54.4
2018-09-30 03:00:00+00:00 0.7 59.5
2018-09-30 04:00:00+00:00 0.7 50.7
2018-09-30 05:00:00+00:00 0.4 77.1
3.feed_3.PM10B_UG_M3 3.feed_5975.PM2_5 \
EpochTime
2016-10-31 06:00:00+00:00 9.0 0.0
2016-10-31 07:00:00+00:00 13.0 5.0
2016-10-31 08:00:00+00:00 7.0 9.0
2016-10-31 09:00:00+00:00 11.0 3.0
2016-10-31 10:00:00+00:00 10.0 9.0
... ... ...
2018-09-30 01:00:00+00:00 11.0 5.0
2018-09-30 02:00:00+00:00 21.0 7.0
2018-09-30 03:00:00+00:00 33.0 8.0
2018-09-30 04:00:00+00:00 32.0 17.0
2018-09-30 05:00:00+00:00 27.0 18.0
3.feed_27.NO_PPB 3.feed_27.NOY_PPB \
EpochTime
2016-10-31 06:00:00+00:00 0.1 2.6
2016-10-31 07:00:00+00:00 -1.0 -1.0
2016-10-31 08:00:00+00:00 0.2 2.1
2016-10-31 09:00:00+00:00 0.1 3.1
2016-10-31 10:00:00+00:00 0.1 2.5
... ... ...
2018-09-30 01:00:00+00:00 0.1 12.1
2018-09-30 02:00:00+00:00 0.2 13.5
2018-09-30 03:00:00+00:00 0.6 13.8
2018-09-30 04:00:00+00:00 0.6 11.4
2018-09-30 05:00:00+00:00 2.0 13.1
3.feed_27.CO_PPB 3.feed_27.SO2_PPB
EpochTime
2016-10-31 06:00:00+00:00 -1.0 0.2
2016-10-31 07:00:00+00:00 106.1 0.0
2016-10-31 08:00:00+00:00 105.8 -1.0
2016-10-31 09:00:00+00:00 111.7 0.0
2016-10-31 10:00:00+00:00 127.2 0.0
... ... ...
2018-09-30 01:00:00+00:00 301.0 0.0
2018-09-30 02:00:00+00:00 357.7 0.0
2018-09-30 03:00:00+00:00 373.6 0.0
2018-09-30 04:00:00+00:00 381.0 0.0
2018-09-30 05:00:00+00:00 377.7 0.0
[16776 rows x 43 columns]
Task 5: Preprocess Smell Data#
In this task, we will preprocess the smell data. First, we need to load the raw smell data.
smell_raw = pd.read_csv("smellpgh-v1/smell_raw.csv").set_index("EpochTime")
smell_raw
| feelings_symptoms | smell_description | smell_value | zipcode | |
|---|---|---|---|---|
| EpochTime | ||||
| 1477935134 | NaN | NaN | 1 | 15221 |
| 1477956180 | NaN | Woodsmoke | 2 | 15218 |
| 1477956293 | NaN | Wood smoke | 3 | 15218 |
| 1477973293 | Eye irritation, nose burns, headache, woke me up | Industrial | 5 | 15207 |
| 1478001989 | NaN | Industrial smoke | 2 | 15213 |
| ... | ... | ... | ... | ... |
| 1538248172 | NaN | Sour sewage | 3 | 15213 |
| 1538255258 | Coughing | Smoke | 2 | 15104 |
| 1538268796 | NaN | Like a burning candle | 3 | 15232 |
| 1538281653 | No | Greasy air | 3 | 15222 |
| 1538282980 | Eye irritation | Wood smoke and gun powder very Smokey too as f... | 5 | 15217 |
10353 rows × 4 columns
The meaning of EpochTime is explained in the previous task. Other columns mean the self-reported symptoms, descriptions of smell, severity ratings (the smell_value column), and the zipcode where the report is submitted in Pittsburgh, Pennsylvania. For example, the second row means that the smell report was submitted from the 15218 zipcode with wood smoke description and severity rating 2. For more description about the smell, please check the Smell Pittsburgh website.
Next, we need to resample the smell data so that they can be used for modeling. Our goal is to have a dataframe that looks like the following:
df_smell = answer_preprocess_smell(smell_raw)
df_smell
| smell_value | |
|---|---|
| EpochTime | |
| 2016-10-31 23:00:00+00:00 | 3.0 |
| 2016-11-01 00:00:00+00:00 | 0.0 |
| 2016-11-01 01:00:00+00:00 | 0.0 |
| 2016-11-01 02:00:00+00:00 | 0.0 |
| 2016-11-01 03:00:00+00:00 | 0.0 |
| ... | ... |
| 2018-09-30 00:00:00+00:00 | 3.0 |
| 2018-09-30 01:00:00+00:00 | 0.0 |
| 2018-09-30 02:00:00+00:00 | 0.0 |
| 2018-09-30 03:00:00+00:00 | 0.0 |
| 2018-09-30 04:00:00+00:00 | 8.0 |
16758 rows × 1 columns
In the latest row, the timestamp is 2018-09-30 04:00:00+00:00, which means this row contains the data from 3:00 to 4:00 on September 30 in 2018. This row has smell_value 8, which means the sum of smell report ratings in the above mentioned time range. Notice that the expected output ignores all smell ratings from 1 to 2. This is becasue we only want the ratings that indicate bad smell, which will be further explained below.
Assignment for Task 5#
Your task (which is your assignment) is to write a function to do the following:
First, remove the
feelings_symptoms,smell_description, andzipcodecolumns since we do not need them.Hint: Use the
pandas.DataFrame.dropfunction. Type?pd.DataFrame.dropin a code cell for more information.
We only want the reports that indicate bad smell. You need to select only the reports with rating 3, 4, or 5 in the
smell_valuecolumn.Then, we want to know the severity of bad smell within an hour in the future. For example, at time 8:00, we want to know the sum of smell values between 8:00 and 9:00. So you need to resample the data by computing the hourly sum of smell values from the “future” hour.
Hint: Use the
pandas.to_datetimefunction when converting timestamps to datetime objects. Type?pd.to_datetimein a code cell for more information.Hint: Use the
pandas.DataFrame.resamplefunction to resample data. Type?pd.DataFrame.resamplein a code cell for more information.
Finally, fill in the missing data with the value 0. The reason is that missing data means there are no smell reports (provided by citizens) within an hour, so we assume that there is no bad smell within this period of time. Notice that this is an assumption and also a limitation since citizens rarely report good smell.
Hint: Use the
pandas.DataFrame.fillnafunction when treating missing values. Type?pd.DataFrame.fillnain a code cell for more information.
Notice that you need to convert the column types in the dataframe to float to avoid errors when checking if the answers match the desired output. You can use the
pandas.DataFrame.astypefunction to do thisdf = df.astype(float).
def preprocess_smell(df):
"""
Preprocess smell data.
Parameters
----------
df : pandas.DataFrame
The raw smell reports data.
Returns
-------
pandas.DataFrame
The preprocessed smell data.
"""
###################################
# Fill in your answer here
return None
###################################
The code below tests if the output of your function matches the expected output.
check_answer_df(preprocess_smell(smell_raw), df_smell, n=1)
Test case 1 failed.
Your output is:
None
Expected output is:
smell_value
EpochTime
2016-10-31 23:00:00+00:00 3.0
2016-11-01 00:00:00+00:00 0.0
2016-11-01 01:00:00+00:00 0.0
2016-11-01 02:00:00+00:00 0.0
2016-11-01 03:00:00+00:00 0.0
... ...
2018-09-30 00:00:00+00:00 3.0
2018-09-30 01:00:00+00:00 0.0
2018-09-30 02:00:00+00:00 0.0
2018-09-30 03:00:00+00:00 0.0
2018-09-30 04:00:00+00:00 8.0
[16758 rows x 1 columns]
Now, we can plot the distribution of smell values by using the pandas.DataFrame.plot function.
fig = df_smell.plot(kind="hist", bins=20, ylim=(0,100), edgecolor="black").set_yticks([0,50,100], labels=["0","50",">100"])
From the plot above, we can observe that a lot of the time, the smell values are fairly low. This means that smell events only happen occasionally, and thus our dataset is highly imbalanced.
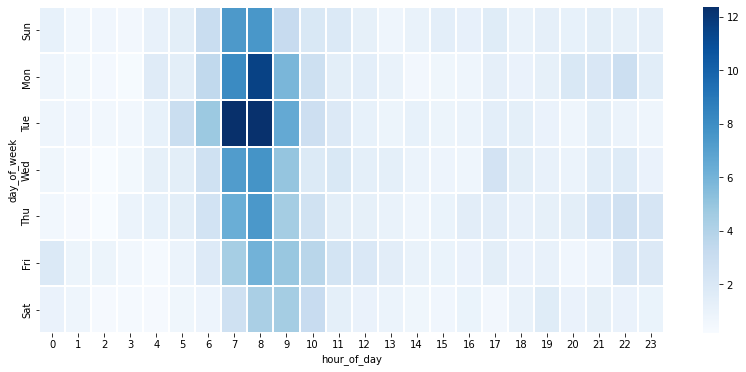
We can also plot the average number of smell reports distributed by the day of week (Sunday to Saturday) and the hour of day (0 to 23), using a provided function plot_smell_by_day_and_hour in the utility file.
plot_smell_by_day_and_hour(df_smell)
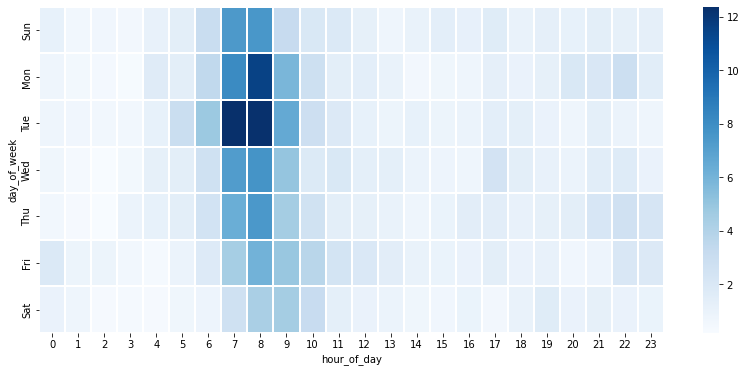
From the plot above, we can observe that citizens tend to report smell in the morning. This suggests that there is not enough data at night time, so we should develop and evaluate the model using only the data in day time.
Task 6: Prepare Features and Labels#
Now we have the preprocessed data in the df_sensor and df_smell variables. Our next task is to prepare features and labels for modeling, as shown in the figure below.
Our goal is to construct two data frames, df_x and df_y, that represent the features and labels, respectively. First, we will deal with the sensor data. We need a function to insert columns (that indicate previous n_hr hours of sensor) to the existing data frame, where n_hr should be a parameter that we can control. We provide the insert_previous_data_to_cols function in the utility file to do this.
The code below shows a test case, which is a part of the sensor data.
# Below is an example input.
df_sensor_example_in = df_sensor[["3.feed_1.SONICWS_MPH"]][0:5]
df_sensor_example_in
| 3.feed_1.SONICWS_MPH | |
|---|---|
| EpochTime | |
| 2016-10-31 06:00:00+00:00 | 3.6 |
| 2016-10-31 07:00:00+00:00 | 3.5 |
| 2016-10-31 08:00:00+00:00 | 3.4 |
| 2016-10-31 09:00:00+00:00 | 2.1 |
| 2016-10-31 10:00:00+00:00 | 2.2 |
# Below is the expected output of the above example input.
df_sensor_example_out = insert_previous_data_to_cols(df_sensor_example_in, n_hr=2)
df_sensor_example_out
| 3.feed_1.SONICWS_MPH_pre_1h | 3.feed_1.SONICWS_MPH_pre_2h | 3.feed_1.SONICWS_MPH_pre_3h | |
|---|---|---|---|
| EpochTime | |||
| 2016-10-31 08:00:00+00:00 | 3.4 | 3.5 | 3.6 |
| 2016-10-31 09:00:00+00:00 | 2.1 | 3.4 | 3.5 |
| 2016-10-31 10:00:00+00:00 | 2.2 | 2.1 | 3.4 |
The reason that there are 2 less rows in the expected output is because we set n_hr=2, which means there are missing data in the original first and second row (because there was no previous data for these rows). So in the code, we removed these rows.
Notice that the insert_previous_data_to_cols function added suffixes to the column names to indicate the number of hours that the sensor measurements came from previously. Pay attention to the meaning of time range here.
For example, in the first row, the
3.feed_1.SONICWS_MPH_pre_1hcolumn has value3.4, which means the average reading of wind speed (in unit MPH) between the current time stamp (which is8:00) and the previous 1 hour (which is7:00).In the second column of the first row, the
3.feed_1.SONICWS_MPH_pre_2hhas value3.5, which means the average reading of wind speed between the previous 1 hour (which is7:00) and 2 hours (which is6:00).It is important to note here that suffix
pre_2hdoes NOT mean the average rating within 2 hours between the current time stamp and the time that is 2 hours ago.
Then, we also need a function to convert wind direction into sine and cosine components, which is a common technique for encoding cyclical features (i.e., any that circulates within a set of values, such as hours of the day, days of the week). The formula is below:
There are several reasons to do this instead of using the original wind direction degrees (that range from 0 to 360). First, by applying sine and cosine to the degrees, we can transform the original data to a continuous variable. The original data is not continuous since there are no values below 0 or above 360, and there is no information to tell that 0 degrees and 360 degrees are the same. Second, the decomposed sine and cosine components allow us to inspect the effect of wind on the north-south and east-west directions separately, which may help us explain the importance of wind directions. See the code for function convert_wind_direction in the utility file for achieving this.
The code below shows a test case, which is a part of the sensor data.
# Below is an example input.
df_wind_example_in = df_sensor[["3.feed_1.SONICWD_DEG"]][0:5]
df_wind_example_in
| 3.feed_1.SONICWD_DEG | |
|---|---|
| EpochTime | |
| 2016-10-31 06:00:00+00:00 | 343.0 |
| 2016-10-31 07:00:00+00:00 | 351.0 |
| 2016-10-31 08:00:00+00:00 | 359.0 |
| 2016-10-31 09:00:00+00:00 | 5.0 |
| 2016-10-31 10:00:00+00:00 | 41.0 |
# Below is the expected output of the above example input.
df_wind_example_out = convert_wind_direction(df_wind_example_in)
df_wind_example_out
| 3.feed_1.SONICWD_DEG_cosine | 3.feed_1.SONICWD_DEG_sine | |
|---|---|---|
| EpochTime | ||
| 2016-10-31 06:00:00+00:00 | 0.956305 | -0.292372 |
| 2016-10-31 07:00:00+00:00 | 0.987688 | -0.156434 |
| 2016-10-31 08:00:00+00:00 | 0.999848 | -0.017452 |
| 2016-10-31 09:00:00+00:00 | 0.996195 | 0.087156 |
| 2016-10-31 10:00:00+00:00 | 0.754710 | 0.656059 |
We have dealt with the sensor data. Next, we will deal with the smell data. We need a function to sum up smell values in the future hours, where n_hr should be a parameter that we can control. The code below shows a test case, which is a part of the smell data.
# Below is an example input.
df_smell_example_in = df_smell[107:112]
df_smell_example_in
| smell_value | |
|---|---|
| EpochTime | |
| 2016-11-05 10:00:00+00:00 | 8.0 |
| 2016-11-05 11:00:00+00:00 | 13.0 |
| 2016-11-05 12:00:00+00:00 | 40.0 |
| 2016-11-05 13:00:00+00:00 | 22.0 |
| 2016-11-05 14:00:00+00:00 | 4.0 |
# Below is the expected output of the above example input.
df_smell_example_out1 = answer_sum_current_and_future_data(df_smell_example_in, n_hr=1)
df_smell_example_out1
| smell_value | |
|---|---|
| EpochTime | |
| 2016-11-05 10:00:00+00:00 | 21.0 |
| 2016-11-05 11:00:00+00:00 | 53.0 |
| 2016-11-05 12:00:00+00:00 | 62.0 |
| 2016-11-05 13:00:00+00:00 | 26.0 |
# Below is another expected output with a different n_hr.
df_smell_example_out2 = answer_sum_current_and_future_data(df_smell_example_in, n_hr=3)
df_smell_example_out2
| smell_value | |
|---|---|
| EpochTime | |
| 2016-11-05 10:00:00+00:00 | 83.0 |
| 2016-11-05 11:00:00+00:00 | 79.0 |
In the output above, notice that row 2016-11-05 10:00:00+00:00 has smell value 83, and the setting is n_hr=3, which means the sum of smell values within n_hr+1 hours (i.e., from 10:00 to 14:00) is 83. Pay attention to this setup since it can be confusing. The reason of n_hr+1 (but not n_hr) is because the input data already indicates the sum of smell values within the future 1 hour.
# Below is another expected output when n_hr is 0.
df_smell_example_out3 = answer_sum_current_and_future_data(df_smell_example_in, n_hr=0)
df_smell_example_out3
| smell_value | |
|---|---|
| EpochTime | |
| 2016-11-05 10:00:00+00:00 | 8.0 |
| 2016-11-05 11:00:00+00:00 | 13.0 |
| 2016-11-05 12:00:00+00:00 | 40.0 |
| 2016-11-05 13:00:00+00:00 | 22.0 |
| 2016-11-05 14:00:00+00:00 | 4.0 |
Assignment for Task 6#
Your task (which is your assignment) is to write a function to do the following:
First, perform a windowing operation to sum up smell values within a specified
n_hrtime window.Hint: Use the
pandas.DataFrame.rollingfunction when summing up values within a window. Type?pd.DataFrame.rollingin a code cell for more information.Hint: Use the
pandas.DataFrame.shiftfuction to shift the rolled data backn_hrhours because we want to sum up the values in the future (the rolling function operates on the values in the past). Type?pd.DataFrame.shiftin a code cell for more information.
Finally, Remove the last
n_hrhours of data because they have the wrong data due to shifting. For example, the last row does not have data in the future to operate if we setn_hr=1.Hint: Use
pandas.DataFrame.ilocto select the rows that you want to keep. Type?pd.DataFrame.ilocin a code cell for more information.
You need to handle the edge case when
n_hr=0, which should output the original data frame.Notice that you need to convert the column types in the dataframe to float to avoid errors when checking if the answers match the desired output. You can use the
pandas.DataFrame.astypefunction to do thisdf = df.astype(float).
def sum_current_and_future_data(df, n_hr=0):
"""
Sum up data in the current and future hours.
Parameters
----------
df : pandas.DataFrame
The preprocessed smell data.
n_hr : int
Number of hours that we want to sum up the future smell data.
Returns
-------
pandas.DataFrame
The transformed smell data.
"""
###################################
# Fill in your answer here
return None
###################################
The code below tests if the output of your function matches the expected output.
check_answer_df(sum_current_and_future_data(df_smell_example_in, n_hr=1), df_smell_example_out1, n=1)
Test case 1 failed.
Your output is:
None
Expected output is:
smell_value
EpochTime
2016-11-05 10:00:00+00:00 21.0
2016-11-05 11:00:00+00:00 53.0
2016-11-05 12:00:00+00:00 62.0
2016-11-05 13:00:00+00:00 26.0
check_answer_df(sum_current_and_future_data(df_smell_example_in, n_hr=3), df_smell_example_out2, n=2)
Test case 2 failed.
Your output is:
None
Expected output is:
smell_value
EpochTime
2016-11-05 10:00:00+00:00 83.0
2016-11-05 11:00:00+00:00 79.0
check_answer_df(sum_current_and_future_data(df_smell_example_in, n_hr=0), df_smell_example_out3, n=3)
Test case 3 failed.
Your output is:
None
Expected output is:
smell_value
EpochTime
2016-11-05 10:00:00+00:00 8.0
2016-11-05 11:00:00+00:00 13.0
2016-11-05 12:00:00+00:00 40.0
2016-11-05 13:00:00+00:00 22.0
2016-11-05 14:00:00+00:00 4.0
Finally, we need a function to compute the features and labels, based on the insert_previous_data_to_cols and sum_current_and_future_data functions. The code is below.
def compute_feature_label(df_smell, df_sensor, b_hr_sensor=0, f_hr_smell=0):
"""
Compute features and labels from the smell and sensor data.
Parameters
----------
df_smell : pandas.DataFrame
The preprocessed smell data.
df_sensor : pandas.DataFrame
The preprocessed sensor data.
b_hr_sensor : int
Number of hours that we want to insert the previous sensor data.
f_hr_smell : int
Number of hours that we want to sum up the future smell data.
Returns
-------
df_x : pandas.DataFrame
The features that we want to use for modeling.
df_y : pandas.DataFrame
The labels that we want to use for modeling.
"""
# Copy data frames to prevent editing the original ones.
df_smell = df_smell.copy(deep=True)
df_sensor = df_sensor.copy(deep=True)
# Replace -1 values in sensor data to NaN
df_sensor[df_sensor==-1] = np.nan
# Convert all wind directions.
df_sensor = convert_wind_direction(df_sensor)
# Scale sensor data and fill in missing values
df_sensor = (df_sensor - df_sensor.mean()) / df_sensor.std()
df_sensor = df_sensor.round(6)
df_sensor = df_sensor.fillna(-1)
# Insert previous sensor data as features.
# Noice that the df_sensor is already using the previous data.
# So b_hr_sensor=0 means using data from the previous 1 hour.
# And b_hr_sensor=n means using data from the previous n+1 hours.
df_sensor = insert_previous_data_to_cols(df_sensor, b_hr_sensor)
# Sum up current and future smell values as label.
# Notice that the df_smell is already the data from the future 1 hour.
# (as indicated in the preprocessing phase of smell data)
# So f_hr_smell=0 means using data from the future 1 hour.
# And f_hr_smell=n means using data from the future n+1 hours.
df_smell = answer_sum_current_and_future_data(df_smell, f_hr_smell)
# Add suffix to the column name of the smell data to prevent confusion.
# See the description above for the reason of adding 1 to the f_hr_smell.
df_smell.columns += "_future_" + str(f_hr_smell+1) + "h"
# Filter the DataFrame based on the time range
# We only want the prediction in the daytime
# So 5:00 to 11:00 covers the 8-hour prediction from 5:00 to 19:00
df_sensor = df_sensor.between_time('05:00:00', '11:00:00')
df_smell = df_smell.between_time('05:00:00', '11:00:00')
# We need to first merge these two timestamps based on the available data.
# In this way, we synchronize the time stamps in the sensor and smell data.
# This also means that the sensor and smell data have the same number of data points.
df = pd.merge_ordered(df_sensor.reset_index(), df_smell.reset_index(), on=df_smell.index.name, how="inner", fill_method=None)
# Sanity check: there should be no missing data.
assert df.isna().sum().sum() == 0, "Error! There is missing data."
# Separate features (x) and labels (y).
df_x = df[df_sensor.columns].copy()
df_y = df[df_smell.columns].copy()
return df_x, df_y
We will use the sensor data within the previous 3 hours to predict bad smell within the future 8 hours. To use the compute_feature_label function that we just build, we need to set b_hr_sensor=2 and f_hr_smell=7 because originally df_sensor already contains data from the previous 1 hour, and df_smell already contains data from the future 1 hour.
Note that b_hr_sensor=n means that we want to insert previous n+1 hours of sensor data , and f_hr_smell=m means that we want to sum up the smell values of the future m+1 hours. For example, suppose that the current time is 8:00, setting b_hr_sensor=2 means that we use all sensor data from 5:00 to 8:00 (as features df_x in prediction), and setting f_hr_smell=7 means that we sum up the smell values from 8:00 to 16:00 (as labels df_y in prediction).
Notice that we also filter the dataframe to only the data points from 5:00 to 11:00. This is because citizens only reported smell in the daytime, according to our plot, about the distribution of smell reports. Since we do an 8-hour prediction, the range covers the prediction from 5:00 to 19:00.
df_x, df_y = compute_feature_label(df_smell, df_sensor, b_hr_sensor=2, f_hr_smell=7)
Below is the data frame of features (i.e., the predictor variable). There are negative float numbers because the compute_feature_label function scales the sensor data by subtracting its mean value and dividing it by the standard deviation.
df_x
| 3.feed_1.SO2_PPM_pre_1h | 3.feed_1.H2S_PPM_pre_1h | 3.feed_1.SIGTHETA_DEG_pre_1h | 3.feed_1.SONICWS_MPH_pre_1h | 3.feed_23.CO_PPM_pre_1h | 3.feed_23.PM10_UG_M3_pre_1h | 3.feed_29.PM10_UG_M3_pre_1h | 3.feed_29.PM25_UG_M3_pre_1h | 3.feed_11067.CO_PPB..3.feed_43.CO_PPB_pre_1h | 3.feed_11067.NO2_PPB..3.feed_43.NO2_PPB_pre_1h | ... | 3.feed_1.SONICWD_DEG_cosine_pre_3h | 3.feed_1.SONICWD_DEG_sine_pre_3h | 3.feed_11067.SONICWD_DEG..3.feed_43.SONICWD_DEG_cosine_pre_3h | 3.feed_11067.SONICWD_DEG..3.feed_43.SONICWD_DEG_sine_pre_3h | 3.feed_28.SONICWD_DEG_cosine_pre_3h | 3.feed_28.SONICWD_DEG_sine_pre_3h | 3.feed_26.SONICWD_DEG_cosine_pre_3h | 3.feed_26.SONICWD_DEG_sine_pre_3h | 3.feed_3.SONICWD_DEG_cosine_pre_3h | 3.feed_3.SONICWD_DEG_sine_pre_3h | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.273112 | -0.403688 | 2.446633 | -1.112877 | 0.683606 | -0.087222 | -0.509957 | -0.395826 | -0.708135 | -0.390474 | ... | 0.234896 | 1.520373 | -0.035828 | 1.679768 | 0.456533 | 1.732861 | 1.163302 | 0.894968 | -0.662573 | 1.282593 |
| 1 | -0.273112 | -0.403688 | 1.401940 | -1.155694 | 0.147335 | -0.345973 | -0.458211 | -0.305936 | -0.708678 | -0.471815 | ... | 1.373130 | 0.820120 | -0.745391 | 1.313159 | -0.385374 | 1.598479 | 1.178214 | 0.842876 | 0.412296 | 1.383084 |
| 2 | -0.273112 | -0.403688 | -0.121897 | -1.112877 | 0.147335 | -0.259723 | -0.354720 | -0.216045 | -1.000000 | -0.341669 | ... | 0.619867 | 1.426571 | -0.182544 | 1.642675 | -0.196810 | 1.675257 | 1.235255 | 0.274625 | 1.340881 | -0.562828 |
| 3 | -0.273112 | -0.403688 | 1.001344 | -1.198511 | 0.147335 | -0.345973 | -0.406466 | -0.216045 | -0.904967 | -1.000000 | ... | 0.763840 | -0.987118 | 1.109181 | 1.411716 | -0.721761 | 1.369820 | 1.238412 | 0.411473 | 1.529028 | 0.134272 |
| 4 | -0.273112 | -0.403688 | 0.875667 | -1.112877 | 0.147335 | -0.432224 | -0.509957 | -0.395826 | -0.921799 | -1.000000 | ... | -0.600537 | 1.417213 | 0.850317 | 1.569438 | 0.151969 | 1.743579 | 1.237780 | 0.438851 | 1.447792 | -0.349233 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4881 | -0.273112 | -0.403688 | 0.019490 | -0.384991 | -0.388936 | 0.171529 | 1.973834 | 1.761545 | -1.000000 | 0.471745 | ... | -0.476321 | 1.460204 | -1.023648 | 0.952013 | -0.954863 | -0.543406 | 1.119099 | 1.022337 | -1.044255 | 1.035923 |
| 4882 | -0.273112 | -0.403688 | 0.058764 | -0.556258 | -0.388936 | 0.171529 | 0.628447 | 0.413188 | 0.644440 | -1.000000 | ... | -0.191071 | 1.520373 | -1.203889 | 0.292969 | -1.056549 | -0.365910 | -1.416469 | 0.997222 | -0.885482 | 1.158693 |
| 4883 | -0.273112 | -0.403688 | -1.221574 | -0.641892 | -0.925207 | -0.087222 | -0.199483 | -0.126155 | -0.447774 | -0.016303 | ... | 1.176881 | 1.071002 | -1.134067 | -0.210812 | -0.982575 | -0.500401 | 0.867220 | -0.686105 | -0.709046 | 1.260613 |
| 4884 | -0.273112 | -0.403688 | -0.436091 | -0.984426 | -0.925207 | -0.432224 | -0.354720 | -0.305936 | -0.270218 | -0.341669 | ... | 1.244103 | -0.620310 | 1.088914 | -0.943229 | -0.643817 | -0.879555 | -0.143874 | -1.185113 | 1.529946 | 0.087461 |
| 4885 | -0.273112 | -0.403688 | -1.300122 | -0.898793 | -0.925207 | -0.345973 | -0.509957 | -0.395826 | 0.352585 | 0.422940 | ... | 1.122753 | -0.745145 | 1.647367 | -0.087669 | 0.606314 | -1.147345 | 1.076798 | -0.352608 | 1.377335 | 0.675460 |
4886 rows × 144 columns
Below is the data frame of labels (i.e., the response variable).
df_y
| smell_value_future_8h | |
|---|---|
| 0 | 3.0 |
| 1 | 6.0 |
| 2 | 6.0 |
| 3 | 34.0 |
| 4 | 40.0 |
| ... | ... |
| 4881 | 4.0 |
| 4882 | 0.0 |
| 4883 | 0.0 |
| 4884 | 0.0 |
| 4885 | 0.0 |
4886 rows × 1 columns
Task 7: Train and Evaluate Models#
We have processed raw data and prepared the compute_feature_label function to convert smell and sensor data into features df_x and labels df_y. In this task, you will work on training basic and advanced models to predict bad smell events (i.e., the situation that the smell value is high) using the sensor data from air quality monitoring stations.
First, let us threshold the features to make them binary for our classification task. We will use value 40 as the threshold to indicate a smell event. The threshold 40 was used in the Smell Pittsburgh research paper. It is equivalent to the situation that 10 people reported smell with rating 4 within 8 hours.
df_y_40 = (df_y>=40).astype(int)
df_y_40
| smell_value_future_8h | |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 1 |
| ... | ... |
| 4881 | 0 |
| 4882 | 0 |
| 4883 | 0 |
| 4884 | 0 |
| 4885 | 0 |
4886 rows × 1 columns
The descriptive statistics below tell us that the dataset is imbalanced, which means that the numbers of data points in the positive and negative label groups have a big difference.
print("There are %d rows with smell events." % (df_y_40.sum().iloc[0]))
print("This means %.2f proportion of the data has smell events." % (df_y_40.sum().iloc[0]/len(df_y_40)))
There are 794 rows with smell events.
This means 0.16 proportion of the data has smell events.
Principal Component Analysis#
We can also plot the result from the Principal Component Analysis (PCA) to check if there are patterns in the data.
PCA is a linear dimensionality reduction technique aiming to transform the original variables into a new set of uncorrelated variables (principal components) that preserve as much information or variability in the dataset as possible. To do so, it applies a linear transformation to the data onto a new coordinate system such that the directions (principal components) that capture the largest variation in the data can be identified.
For more information about PCA, check the slides in the data science course and this StatQuest video. If you are interested in the mathematical explanation of PCA, you can check the following hidden block. Otherwise, please feel free to skip the math.
Click the button to show the math for PCA
Principal components are the eigenvectors of the covariance matrix of the centered data. The magnitude of their corresponding eigenvalues indicates the explained variance that each principal component captures. That way, the eigenvectors with the \(n\) highest principal components will be chosen as principal components.
The step to apply PCA with \(n\) components to a dataset \(X\) are the following:
Calculate covariance matrix of the centered data:
Subtract the mean (\(\mu_X\)) of each feature
\[ \bar{X} = X - \mu_X, \]and compute the covariance matrix of the centered data \(\bar{X}\):
\[ C = \frac{1}{N} \bar{X}^T \bar{X}.\]Compute Eigenvalues and Eigenvectors:
Derive the eigenvalues \(\{\lambda_i\}\) and eigenvectors \(\{v_i\}\) of the covariance matrix \(C\). Each eigenvector represents a principal component, and its corresponding eigenvalue indicates the variance explained by that principal component.
Choose the principal components
Order the eigenvalues in descending order.
\[ \lambda_1 \geq \lambda_2 \geq \ldots \geq \lambda_D \]and select \(v_1\), \(v_2\), …, \(v_n\) as principal components.
Data Transformation:
Use the original data \(X\) and the chosen principal components to obtain the transformed data \(X'\):
\[ X' = X P_k \]where \(P_n\) is the matrix with the first \(n\) eigenvectors as columns.
Dimensionality reduction techiniques are often used to visualize larger-dimensional data in a 2D or 3D space. Let’s apply PCA to our example.
The get_pca_result function in the utility file creates a dataframe with the n principal components in the dataset.
The code below prints the outputs from the get_pca_result function.
df_pc_pca, df_r_pca = get_pca_result(df_x, df_y_40, n=3)
print(df_pc_pca)
print(df_r_pca)
PC1 PC2 PC3 y size
0 1.196087 7.271439 -2.257653 0 15
1 0.593383 6.946370 -0.977864 0 15
2 0.296583 6.621512 -0.595488 0 15
3 -0.578922 6.099083 -0.427022 0 15
4 -0.840017 6.072922 -0.743430 1 15
... ... ... ... .. ...
4881 10.313021 -4.046014 -1.285547 0 15
4882 6.350177 -3.474608 -0.100781 0 15
4883 1.848117 -1.093777 2.008447 0 15
4884 -1.596779 1.475376 3.049797 0 15
4885 -2.214993 3.127917 2.881875 0 15
[4886 rows x 5 columns]
var pc
0 0.302 PC1
1 0.122 PC2
2 0.067 PC3
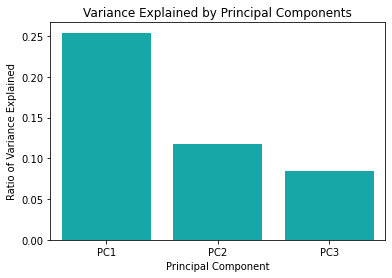
Now let us plot the ratios of explained variances (i.e., the eigenvalues). The intuition is that if the explained variance ratio is larger, the corresponding principal component is more important and can represent more information.
# Plot the eigenvalues.
ax1 = sns.barplot(x="pc",y="var", data=df_r_pca, color="c")
ax1 = ax1.set(xlabel="Principal Component",
ylabel="Ratio of Variance Explained",
title="Variance Explained by Principal Components")
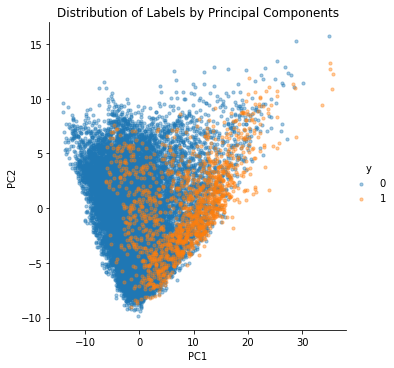
We can also plot the first and second principal components to see the distribution of labels. In the figure below, we see that label 1 (which means having a smell event) is concentrated on one side. However, it looks like labels 0 and 1 do not separate well, which means that the classifier will have difficulty distinguishing these two groups.
# Plot two principal components.
ax2 = sns.lmplot(x="PC1", y="PC2", data=df_pc_pca,
fit_reg=False, hue="y", legend=True,
scatter_kws={"s": 10, "alpha" :0.4})
ax2 = ax2.set(title="Distribution of Labels by Principal Components")
In the interactive figure below, we can zoom in, zoom out, and rotate the view to check the distribution of labels. We can confirm that label 1 is concentrated on one side. But we also observe that there is a large part of the data that may not be separated well by the classifier (especially linear classifiers). We probably need non-linear classifiers to be able to tell the differences between these two groups.
# Use the Plotly package to show the PCA results.
fig = px.scatter_3d(df_pc_pca.sample(n=4000), x="PC1", y="PC2", z="PC3",
color="y", symbol="y", opacity=0.6,
size="size", size_max=15,
category_orders=dict(y=["0", "1"]),
height=700)
fig.show()
Evaluation Metrics#
Next, let us pick a subset of the sensor data (instead of using all of them) and prepare the function for computing the evaluation metrics. Our intuition is that the smell may come from chemical compounds near major pollution sources. From the knowledge of local people, there is a large pollution source, which is the Clairton Mill Works that belongs to the United States Steel Corporation. This pollution source is located at the south part of Pittsburgh. This factory produces petroleum coke, which is a fuel to refine steel. And during the coke refining process, it generates pollutants.
We think that H2S (hydrogen sulfide, smells like rotten eggs) and SO2 (sulfur dioxide, smells like burnt matches) near the pollution source may be good features. So we first select the columns with H2S and SO2 measurements from a monitoring station near this pollution source.
df_x_subset = df_x[["3.feed_28.H2S_PPM_pre_1h", "3.feed_28.SO2_PPM_pre_1h"]]
df_x_subset
| 3.feed_28.H2S_PPM_pre_1h | 3.feed_28.SO2_PPM_pre_1h | |
|---|---|---|
| 0 | -0.426339 | -0.453409 |
| 1 | -0.426339 | -0.453409 |
| 2 | -0.426339 | -0.453409 |
| 3 | -0.426339 | -0.453409 |
| 4 | -0.426339 | -0.453409 |
| ... | ... | ... |
| 4881 | 1.911301 | 2.684586 |
| 4882 | 0.074584 | 0.906389 |
| 4883 | -0.426339 | -0.035010 |
| 4884 | -0.426339 | -0.139610 |
| 4885 | -0.426339 | -0.244209 |
4886 rows × 2 columns
Next, we will train and evaluate a model (F) that maps features (i.e., the sensor readings) to labels (i.e., the smell events). We have the scorer and train_and_evaluate functions ready to help us train and evaluate models. These functions are in the utility file.
The train_and_evaluate function prints the averaged f1-score, averaged precision, averaged recall, and averaged accuracy across all the folds. These metrics are always in the range of zero and one, with zero being the worst and one being the best. We also printed the confusion matrix that contains true positives, false positives, true negatives, and false negatives. To understand the evaluation metrics, let us first take a look at the confusion matrix, explained below:
True Positives
There is a smell event in the real world, and the model correctly predicts that there is a smell event.
False Positives
There is no smell event in the real world, but the model falsely predicts that there is a smell event.
True Negatives
There is no smell event in the real world, and the model correctly predicts that there is no smell event.
False Negatives
There is a smell event in the real world, but the model falsely predicts that there is no smell event.
The accuracy metric is defined in the equation below:
accuracy = (true positives + true negatives) / total number of data points
Accuracy is the number of correct predictions divided by the total number of data points. It is a good metric if the data distribution is not skewed (i.e., the number of data records that have a bad smell and do not have a bad smell is roughly equal). But if the data is skewed, which is the case in our dataset, we will need another set of evaluation metrics: f1-score, precision, and recall. We will use an example later to explain why accuracy is an unfair metric for our dataset.
The precision metric is defined in the equation below:
precision = true positives / (true positives + false positives)
In other words, precision means how precise the prediction is. High precision means that if the model predicts “yes” for smell events, it is highly likely that the prediction is correct. We want high precision because we want the model to be as precise as possible when it says there will be smell events.
Next, the recall metric is defined in the equation below:
recall = true positives / (true positives + false negatives)
In other words, recall means the ability of the model to catch events. High recall means that the model has a low chance to miss the events that happen in the real world. We want high recall because we want the model to catch all smell events without missing them.
Typically, there is a tradeoff between precision and recall, and one may need to choose to go for a high precision but low recall model, or we go for a high recall but low precision model. The tradeoff depends on the context. For example, in medical applications, one may not want to miss the events (e.g., cancer) since the events are connected to patients’ quality of life. In our application of predicting smell events, we may not want the model to make false predictions when saying “yes” to smell events. The reason is that people may lose trust in the prediction model when we make real-world interventions incorrectly, such as sending push notifications to inform the users about the bad smell events.
The f1-score metric is a combination of recall and precision, as indicated below:
f1-score = 2 * (precision * recall) / (precision + recall)
Use the Dummy Classifier#
Now that we have explained the evaluation metrics. Let us first use a dummy classifier that always predicts no smell events. In other words, the dummy classifier never predicts “yes” about the presence of smell events. Later we will guide you through using more advanced machine learning models.
dummy_model = DummyClassifier(strategy="constant", constant=0)
train_and_evaluate(dummy_model, df_x_subset, df_y_40, train_size=1000, test_size=200)
Use model DummyClassifier(constant=0, strategy='constant')
Perform cross-validation, please wait...
================================================
average f1-score: 0.0
average precision: 0.0
average recall: 0.0
average accuracy: 0.83
================================================
The printed message above shows the evaluation result of the dummy classifier. We see that the accuracy is 0.83, which is very high. But the f1-score, precision, and recall are zero since there are no true positives. This is because the Smell Pittsburgh dataset has a skewed distribution of smell events, which means that there are a lot of “no” (i.e., label 0) but only a small part of “yes” (i.e., label 1). This skewed data distribution corresponds to what happened in Pittsburgh. Most of the time, the odors in the city area are OK and not too bad. Occasionally, there can be very bad pollution odors, where many people complain.
By the definition of accuracy, the dummy classifier (which always says “no”) has a very high accuracy of 0.83. This is because only 17% of the data indicate bad smell events. So, you can see that accuracy is not a fair evaluation metric for the Smell Pittsburgh dataset. And instead, we need to go for the f1-score, precision, and recall metrics.
This step uses cross-validation to evaluate the machine learning model, where the data is divided into several parts, and some parts are used for training. Other parts are used for testing. Typically people use K-fold cross-validation, which means that the entire dataset is split into K parts. One part is used for testing (i.e., the testing set), and the other parts are used for training (i.e., the training set). This procedure is repeated K times so that every fold has the chance of being tested. The result is averaged to indicate the performance of the model, for example, averaged accuracy. We can then compare the results for different machine learning pipelines.
However, the script uses a different cross-validation approach, where we only use the previous folds to train the model to test future folds. For example, if we want to test the third fold, we will only use a part of the data from the first and second fold to train the model. The reason is that the Smell Pittsburgh dataset is primarily time-series data, which means the dataset has timestamps for every data record. In other words, things that happened in the past may affect the future. So, in fact, it does not make sense to use the data in the future to train a model to predict what happened in the past. Our time-series cross-validation approach is shown in the following figure.
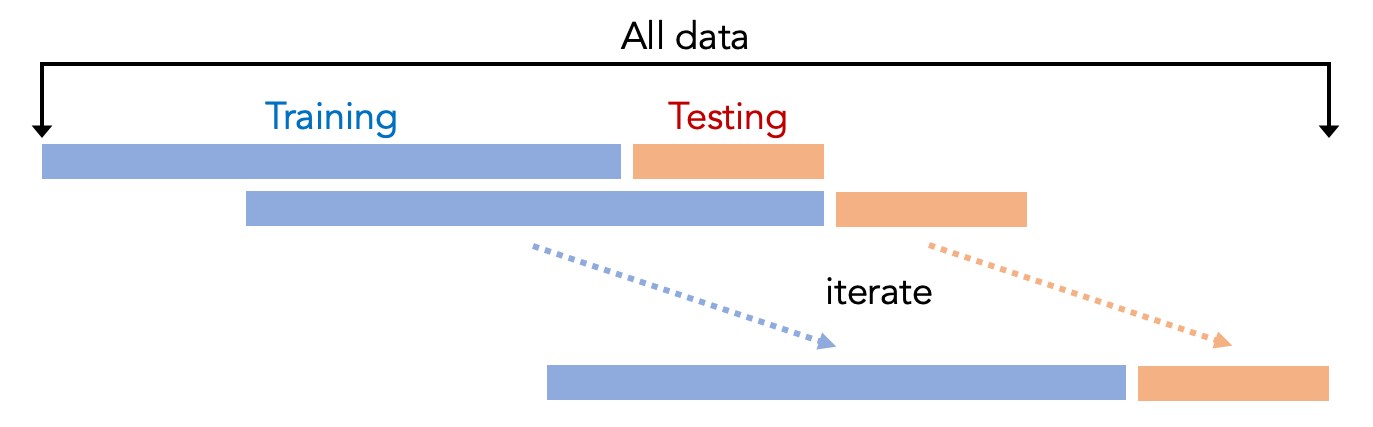
For the train_and_evaluate function, test_size is the number of samples for testing, and train_size is the number of samples for training. We need to set these numbers for time-series cross-validation. For example, setting test_size to 200 means using 200 samples for testing. Setting train_size to 1000 means using 1000 samples for training. So, this means we are using previous 1000 samples of sensor data to train the model, and then use the model to predict the smell events in the future 200 samples. In this setting, every Sunday we can re-train the model with the updated data, so that we have the updated model to predict smell events every week.
Use the Decision Tree Model#
Now, instead of using the dummy classifier, we are going to use a different model. Let us use the Decision Tree model and compare its performance with the dummy classifier.
dt_model = DecisionTreeClassifier()
train_and_evaluate(dt_model, df_x_subset, df_y_40, train_size=1000, test_size=200)
Use model DecisionTreeClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.33
average precision: 0.44
average recall: 0.29
average accuracy: 0.82
================================================
From the printed message above, notice that the Decision Tree model produces non-zero true positives and false positives (compared to the dummy classifier). Also, notice that f1-score, precision, and recall are no longer zero.
Decision Tree is a type of machine learning model. You can think of it as how a medical doctor diagnoses patients. For example, to determine if the patients need treatments, the medical doctor may ask the patients to describe symptoms. Depending on the symptoms, the doctor decides which treatment should be applied for the patient.
One can think of the smell prediction model as an air quality expert who is diagnosing the pollution patterns based on air quality and weather data. The treatment is to send a push notification to citizens to inform them of the presence of bad smell to help people plan daily activities. This decision-making process can be seen as a tree structure as shown in the following figure, where the first node is the most important factor to decide the treatment.
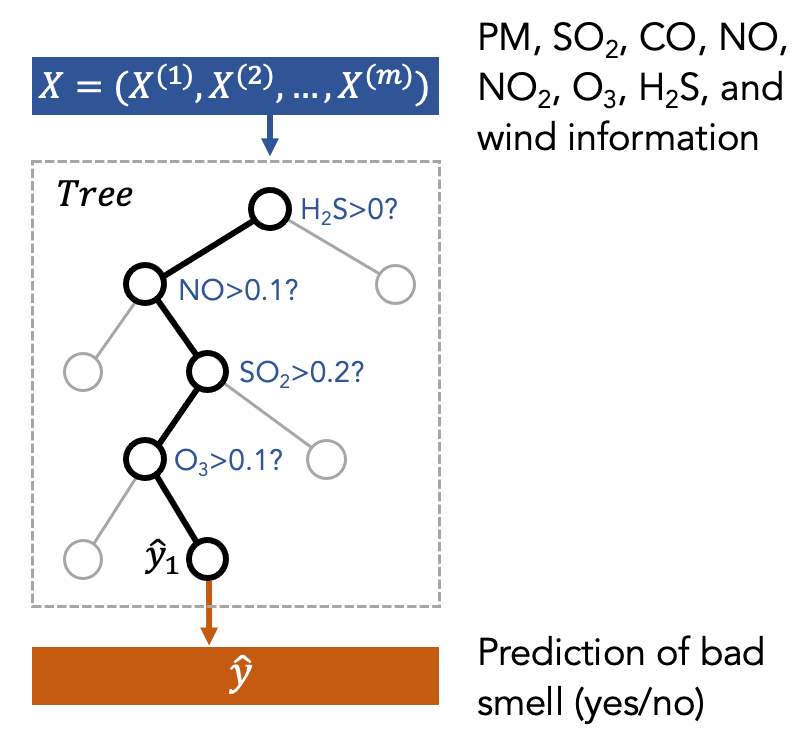
The above figure is just a toy example to show what a decision tree is. In our case, we put the features (X) into the decision tree to train it. Then, the tree will decide which feature to use and what is the threshold to split the data based on the features. This procedure is repeated several times (represented by the depth of the tree). Finally, the model will make a prediction (y) at the final node of the tree.
You can find the visualization of a decision tree (trained using the real data) in Figure 8 in the Smell Pittsburgh paper. More information about the Decision Tree can be found in the following link and paper:
Use the Random Forest Model#
Now that you have tried the Decision Tree model. Let us use a more advanced model, Random Forest, for smell event prediction.
rf_model = RandomForestClassifier()
train_and_evaluate(rf_model, df_x_subset, df_y_40, train_size=1000, test_size=200)
Use model RandomForestClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.34
average precision: 0.45
average recall: 0.29
average accuracy: 0.82
================================================
Notice that the performance of the model does not look much better than the Decision Tree model. And in fact, both models currently have poor performance. This can have several meanings, as indicated in the following list. You will explore some of these questions in the assignment for this task.
Firstly, do we really believe that we are using a good set of features? Is it sufficient to only use the H2S and SO2 features? Is it sufficient to only include the data from the previous hour (i.e., the
"3.feed_28.H2S_PPM_pre_1h"column)?Secondly, the machine learning pipeline uses 1000 samples in the past (i.e.,
train_size=1000) to predict smell events in the future 200 samples (i.e.,test_size=200). Do we believe that 1000 data points are sufficient for training a good model?Finally, the decision tree and random forest models has many hyper-parameters (e.g., maximum depth of tree). Currently, the model uses the default hyper-parameters. Do we believe that the default setting is good?
Now let us take a look at the Random Forest model, which is a type of ensemble model. You can think about the ensemble model as a committee that makes decisions collaboratively, such as using majority voting. For example, to determine the treatment of a patient, we can ask the committee of medical doctors for a collaborative decision. The committee has several members who correspond to various machine learning models. The Random Forest model is a committee that is formed with many decision trees. Each tree is trained using different sets of data, as shown in the following figure.
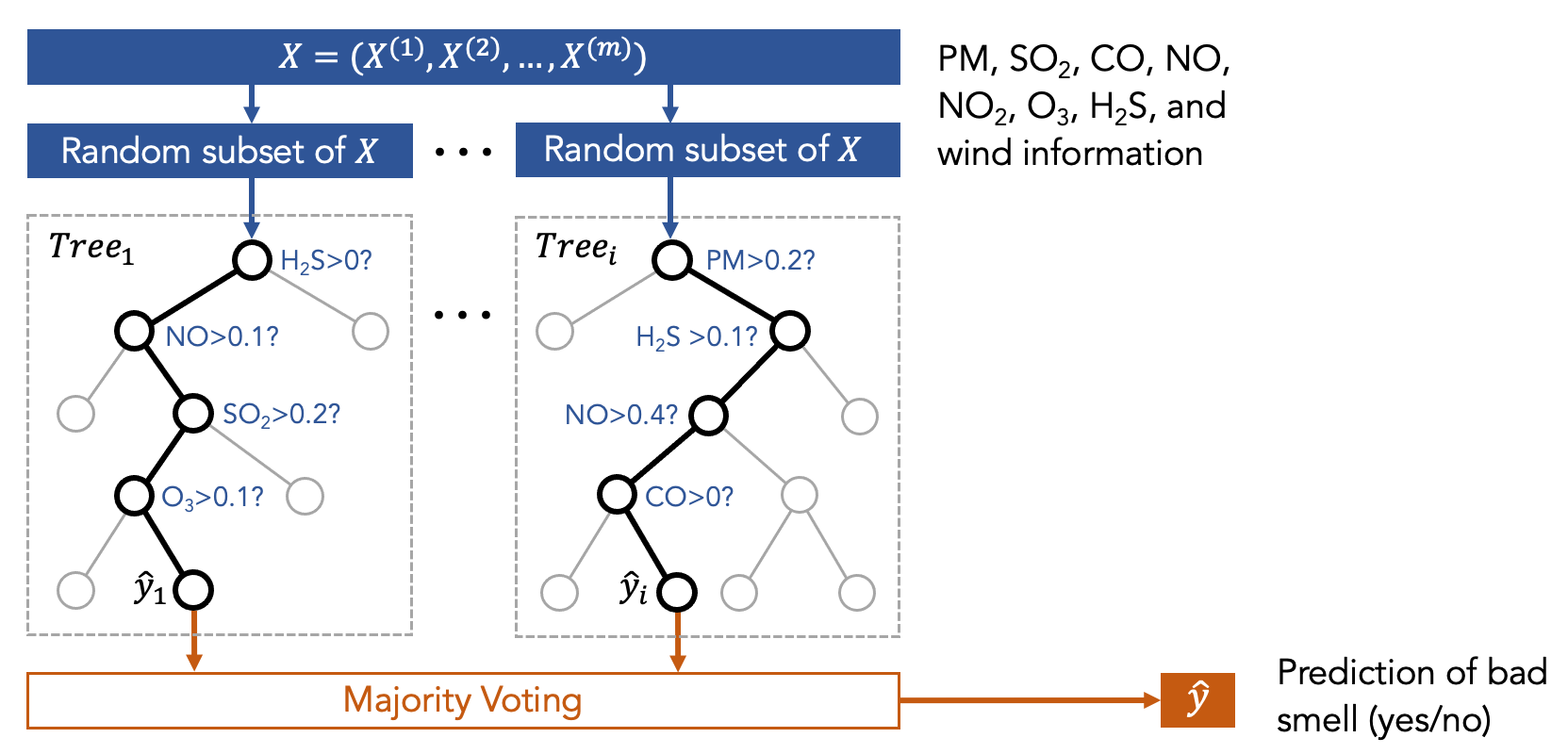
In other words, we first trained many decision trees, and each of them has access to only a part of the data (but not all of the data) that are randomly selected. So, each decision tree sees different sets of features. Then, we ask the committee members (i.e., the decision trees) to make predictions, and the final result is the one that receives the highest votes.
The intuition for having a committee (instead of only a single tree) is that we believe a diverse set of models can make better decisions collaboratively. There is mathematical proof about this intuition, but the proof is outside the scope of this course. More information about the Random Forest model can be found in the following link and paper:
Compute Feature Importance#
After training the model and evaluate its performance, we now have a better understanding about how to predict smell events. However, what if we want to know which are the important features? For example, which pollutants are the major source of the bad smell? Which pollution source is likely related to the bad smell? Under what situation will the pollutants travel to the Pittsburgh city area? This information can be important to help the municipality evaluate air pollution policies. This information can also help local communities to advocate for policy changes.
It turns out that we can permute the data in a specific column to know the importance. If a column (corresponding to a feature) is important, permuting the data specifically for the column will make the model performacne decrease. A higher decrease of a metric (e.g., f1-score) means that the feature is more important. It also means the feature is important for the model to make decisions. So, we can compute the “decrease” of a metric and use it as feature importance. We have provided a function compute_feature_importance in the utility file to do this.
compute_feature_importance(rf_model, df_x_subset, df_y_40, scoring="f1")
Computer feature importance using RandomForestClassifier()
=====================================================================
feature_importance feature_name
0 0.42618 3.feed_28.SO2_PPM_pre_1h
1 0.42095 3.feed_28.H2S_PPM_pre_1h
=====================================================================
Notice that the compute_feature_importance function can take a very long time to run if you use a large amount of training data.
The above code prints feature importance, which indicates the influence of each feature on the model prediction result. Here we use the Random Forest model. For example, in the printed message, the 3.feed_28.H2S_PPM_pre_1h feature has the highest importance. The values in the feature importance here represent the decrease of f1-score (because we use scoring="f1") if we randomly permute the data related to the feature.
For example, if we randomly permute the H2S measurement in the 3.feed_28.H2S_PPM_pre_1h column for all the data records (but keep other features the same), the f1-score of the Random Forest model will drop about 0.42. The intuition is that if a feature is more important, the model performance will decrease more when the feature is randomly permuted (i.e., when the data that is associated with the feature are messed up). More information can be found in the following link:
Notice that to use this technique, the model needs to fit the data reasonably well. Also depending on the number of features you are using, the step of computing the feature importance can take a lot of time.
Assignment for Task 7#
You have learned how to use different models and feature sets. For this assignment, use the knowledge that you learned to conduct experiments to answer the following questions:
Is including sensor data in the past a good idea to help improve model performance?
Hint: Check precision, recall, and F1-score.
Is the wind direction from the air quality monitoring station (i.e., feed 28) that near the pollution source a good feature to predict bad smell?
Hint: Compare the performance of models with different feature sets and check the feature importance.
You need to tweak parameters in the code to conduct a pilot experiment to understand if wind direction is a good feature for predicting the presence of bad smell. Also, you need to inspect if including more data from the previous hours is helpful. Specifically, you need to do the experiment using the combinations of two models (Decision Tree and Random Forest) and four feature sets (as described below). So in total, there should be 8 situations (2 models and 4 feature sets) to compare.
The 1st feature set (S1) below has the H2S and SO2 data from the previous 1 hour:
3.feed_28.H2S_PPM_pre_1h3.feed_28.SO2_PPM_pre_1h
The 2nd feature set (S2) below has the H2S, SO2, and wind data from the previous 1 hour:
3.feed_28.H2S_PPM_pre_1h3.feed_28.SO2_PPM_pre_1h3.feed_28.SONICWD_DEG_sine_pre_1h3.feed_28.SONICWD_DEG_cosine_pre_1h
The 3rd feature set (S3) below has the H2S and SO2 data from the previous 2 hours:
3.feed_28.H2S_PPM_pre_1h3.feed_28.H2S_PPM_pre_2h3.feed_28.SO2_PPM_pre_1h3.feed_28.SO2_PPM_pre_2h
The 4th feature set (S4) below has the H2S, SO2, and wind data from the previous 2 hours:
3.feed_28.H2S_PPM_pre_1h3.feed_28.SO2_PPM_pre_1h3.feed_28.SONICWD_DEG_sine_pre_1h3.feed_28.SONICWD_DEG_cosine_pre_1h3.feed_28.H2S_PPM_pre_2h3.feed_28.SO2_PPM_pre_2h3.feed_28.SONICWD_DEG_sine_pre_2h3.feed_28.SONICWD_DEG_cosine_pre_2h
You can find the explaination of the variables in the Smell Pittsburgh dataset description page.
def experiment(df_x, df_y):
"""
Perform experiments and print the results.
Parameters
----------
df_x : pandas.DataFrame
The data frame that contains all features.
df_y : pandas.DataFrame
The data frame that contains labels.
"""
###################################
# Fill in your answer here
print("None")
###################################
experiment(df_x, df_y_40)
None
You need to write the function above that can do similar things as the following from the answer.
answer_experiment(df_x, df_y_40)
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h']
Use model DecisionTreeClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.33
average precision: 0.44
average recall: 0.29
average accuracy: 0.82
================================================
Computer feature importance using DecisionTreeClassifier()
=====================================================================
feature_importance feature_name
0 0.41955 3.feed_28.SO2_PPM_pre_1h
1 0.27886 3.feed_28.H2S_PPM_pre_1h
=====================================================================
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h', '3.feed_28.SONICWD_DEG_sine_pre_1h', '3.feed_28.SONICWD_DEG_cosine_pre_1h']
Use model DecisionTreeClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.33
average precision: 0.35
average recall: 0.36
average accuracy: 0.78
================================================
Computer feature importance using DecisionTreeClassifier()
=====================================================================
feature_importance feature_name
0 0.62087 3.feed_28.H2S_PPM_pre_1h
1 0.48852 3.feed_28.SONICWD_DEG_sine_pre_1h
2 0.47395 3.feed_28.SO2_PPM_pre_1h
3 0.44296 3.feed_28.SONICWD_DEG_cosine_pre_1h
=====================================================================
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h', '3.feed_28.H2S_PPM_pre_2h', '3.feed_28.SO2_PPM_pre_2h']
Use model DecisionTreeClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.36
average precision: 0.42
average recall: 0.34
average accuracy: 0.81
================================================
Computer feature importance using DecisionTreeClassifier()
=====================================================================
feature_importance feature_name
0 0.52163 3.feed_28.H2S_PPM_pre_1h
1 0.49670 3.feed_28.H2S_PPM_pre_2h
2 0.48037 3.feed_28.SO2_PPM_pre_1h
3 0.39708 3.feed_28.SO2_PPM_pre_2h
=====================================================================
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h', '3.feed_28.H2S_PPM_pre_2h', '3.feed_28.SO2_PPM_pre_2h', '3.feed_28.SONICWD_DEG_sine_pre_1h', '3.feed_28.SONICWD_DEG_cosine_pre_1h', '3.feed_28.SONICWD_DEG_sine_pre_2h', '3.feed_28.SONICWD_DEG_cosine_pre_2h']
Use model DecisionTreeClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.36
average precision: 0.36
average recall: 0.38
average accuracy: 0.8
================================================
Computer feature importance using DecisionTreeClassifier()
=====================================================================
feature_importance feature_name
0 0.56168 3.feed_28.H2S_PPM_pre_1h
1 0.41549 3.feed_28.SONICWD_DEG_sine_pre_1h
2 0.41189 3.feed_28.H2S_PPM_pre_2h
3 0.40296 3.feed_28.SONICWD_DEG_sine_pre_2h
4 0.39819 3.feed_28.SO2_PPM_pre_1h
5 0.37741 3.feed_28.SONICWD_DEG_cosine_pre_1h
6 0.32131 3.feed_28.SONICWD_DEG_cosine_pre_2h
7 0.25142 3.feed_28.SO2_PPM_pre_2h
=====================================================================
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h']
Use model RandomForestClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.33
average precision: 0.44
average recall: 0.29
average accuracy: 0.82
================================================
Computer feature importance using RandomForestClassifier()
=====================================================================
feature_importance feature_name
0 0.41926 3.feed_28.H2S_PPM_pre_1h
1 0.40870 3.feed_28.SO2_PPM_pre_1h
=====================================================================
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h', '3.feed_28.SONICWD_DEG_sine_pre_1h', '3.feed_28.SONICWD_DEG_cosine_pre_1h']
Use model RandomForestClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.36
average precision: 0.44
average recall: 0.34
average accuracy: 0.82
================================================
Computer feature importance using RandomForestClassifier()
=====================================================================
feature_importance feature_name
0 0.55510 3.feed_28.H2S_PPM_pre_1h
1 0.44676 3.feed_28.SO2_PPM_pre_1h
2 0.41902 3.feed_28.SONICWD_DEG_sine_pre_1h
3 0.29714 3.feed_28.SONICWD_DEG_cosine_pre_1h
=====================================================================
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h', '3.feed_28.H2S_PPM_pre_2h', '3.feed_28.SO2_PPM_pre_2h']
Use model RandomForestClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.34
average precision: 0.47
average recall: 0.29
average accuracy: 0.83
================================================
Computer feature importance using RandomForestClassifier()
=====================================================================
feature_importance feature_name
0 0.49783 3.feed_28.H2S_PPM_pre_1h
1 0.41279 3.feed_28.H2S_PPM_pre_2h
2 0.36668 3.feed_28.SO2_PPM_pre_1h
3 0.29157 3.feed_28.SO2_PPM_pre_2h
=====================================================================
Use feature set ['3.feed_28.H2S_PPM_pre_1h', '3.feed_28.SO2_PPM_pre_1h', '3.feed_28.H2S_PPM_pre_2h', '3.feed_28.SO2_PPM_pre_2h', '3.feed_28.SONICWD_DEG_sine_pre_1h', '3.feed_28.SONICWD_DEG_cosine_pre_1h', '3.feed_28.SONICWD_DEG_sine_pre_2h', '3.feed_28.SONICWD_DEG_cosine_pre_2h']
Use model RandomForestClassifier()
Perform cross-validation, please wait...
================================================
average f1-score: 0.36
average precision: 0.5
average recall: 0.32
average accuracy: 0.83
================================================
Computer feature importance using RandomForestClassifier()
=====================================================================
feature_importance feature_name
0 0.28377 3.feed_28.SONICWD_DEG_sine_pre_2h
1 0.26357 3.feed_28.SONICWD_DEG_sine_pre_1h
2 0.25426 3.feed_28.H2S_PPM_pre_1h
3 0.20401 3.feed_28.H2S_PPM_pre_2h
4 0.15889 3.feed_28.SONICWD_DEG_cosine_pre_1h
5 0.15311 3.feed_28.SO2_PPM_pre_1h
6 0.14607 3.feed_28.SONICWD_DEG_cosine_pre_2h
7 0.10152 3.feed_28.SO2_PPM_pre_2h
=====================================================================
Now, think about the following two questions that we asked you.
In your opinion, is including sensor data in the past a good idea to help improve model performance?
In your opinion, is the wind direction from the air quality monitoring station (i.e., feed 28) that near the pollution source a good feature to predict bad smell?
- 1
Credit: this teaching material is created by Yen-Chia Hsu and revised by Alejandro Monroy.