Assignment (Image Data Processing)
Contents
Assignment (Image Data Processing)#
(Last updated: Feb 3, 2025)1
Here is an online version of this notebook in Google Colab. This online version is just for browsing. To work on this notebook, you need to copy a new one to your own Google Colab.
!pip install grad-cam
Requirement already satisfied: grad-cam in /usr/local/lib/python3.10/dist-packages (1.5.0)
Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from grad-cam) (1.25.2)
Requirement already satisfied: Pillow in /usr/local/lib/python3.10/dist-packages (from grad-cam) (9.4.0)
Requirement already satisfied: torch>=1.7.1 in /usr/local/lib/python3.10/dist-packages (from grad-cam) (2.1.0+cu121)
Requirement already satisfied: torchvision>=0.8.2 in /usr/local/lib/python3.10/dist-packages (from grad-cam) (0.16.0+cu121)
Requirement already satisfied: ttach in /usr/local/lib/python3.10/dist-packages (from grad-cam) (0.0.3)
Requirement already satisfied: tqdm in /usr/local/lib/python3.10/dist-packages (from grad-cam) (4.66.2)
Requirement already satisfied: opencv-python in /usr/local/lib/python3.10/dist-packages (from grad-cam) (4.8.0.76)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (from grad-cam) (3.7.1)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.10/dist-packages (from grad-cam) (1.2.2)
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch>=1.7.1->grad-cam) (3.13.1)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.10/dist-packages (from torch>=1.7.1->grad-cam) (4.10.0)
Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch>=1.7.1->grad-cam) (1.12)
Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch>=1.7.1->grad-cam) (3.2.1)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch>=1.7.1->grad-cam) (3.1.3)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch>=1.7.1->grad-cam) (2023.6.0)
Requirement already satisfied: triton==2.1.0 in /usr/local/lib/python3.10/dist-packages (from torch>=1.7.1->grad-cam) (2.1.0)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from torchvision>=0.8.2->grad-cam) (2.31.0)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->grad-cam) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib->grad-cam) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->grad-cam) (4.49.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->grad-cam) (1.4.5)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->grad-cam) (23.2)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->grad-cam) (3.1.1)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib->grad-cam) (2.8.2)
Requirement already satisfied: scipy>=1.3.2 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->grad-cam) (1.11.4)
Requirement already satisfied: joblib>=1.1.1 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->grad-cam) (1.3.2)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from scikit-learn->grad-cam) (3.3.0)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib->grad-cam) (1.16.0)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch>=1.7.1->grad-cam) (2.1.5)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision>=0.8.2->grad-cam) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision>=0.8.2->grad-cam) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision>=0.8.2->grad-cam) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->torchvision>=0.8.2->grad-cam) (2024.2.2)
Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch>=1.7.1->grad-cam) (1.3.0)
# Importing Libraries
import math
import os
import torch
import torchvision
from torch.utils.data import random_split
import torchvision.models as models
import torchvision.utils as utils
from torch.utils.data.dataloader import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.nn.init as init
from torch.autograd import Variable
from torchvision.utils import make_grid
from IPython.display import Image
import base64
import matplotlib.pyplot as plt
from IPython.display import HTML
from pytorch_grad_cam import GradCAM
from pytorch_grad_cam.utils.image import show_cam_on_image
import numpy as np
First, you need to enable GPUs for the notebook in Google Colab:
Navigate to Edit→Notebook Settings
Select GPU from the Hardware Accelerator drop-down
if torch.cuda.is_available():
device = torch.device("cuda") # use CUDA device
elif torch.backends.mps.is_available():
device = torch.device("mps") # use MPS device
else:
device = torch.device("cpu") # use CPU device
device
device(type='cuda')
Make sure that the ouput from the above cell is device(type='cuda'). If you see device(type='cpu'), it means that you did not enable GPU usage on Google Colab. Go to this page and check the “Use GPU as an accelerator” part for details. Please be patient for this tutorial and the assignment, as training neural networks for Computer Vision tasks typically takes a lot of time.
Scenario#
As members of the data science course, you have been tasked with a challenge to give feedback on classifying garbage types for the Gemeente Amsterdam. Gemeente is a Dutch word meaning “municipality”.
Waste management is a critical issue that affects us all. As our population grows (and we know how much the population of Amsterdam is growing) and consumption increases, the amount of waste we generate also increases. One way to manage this waste is to classify the garbage type, making it easier to handle and recycle. However, manually classifying waste is time-consuming and prone to error, which is where deep learning can help.
Deep learning models can be trained to recognize patterns in data and make predictions based on those patterns. In the case of garbage classification, deep learning can help identify the type of garbage based on its physical properties, such as size, shape, and color. By automating this process, we can improve waste management and recycling efficiency.
Your efforts will contribute to improving the waste management and recycling practices of the Gemeente Amsterdam, making a positive impact on the environment and the community. The Gemeente needs your help in making an effective classification system to assist people in waste management.
Load Datasets#
To work with the garbage classification dataset, we need to download the data. We have prepared a GitHub repository with the dataset for you. You will need to also upload the data to Google Colab.
The following code checks if you are using Google Colab or on a local machine with GPU. If you clone the repository to your local machine, there is no need to download the dataset. However, if you are on Google Colab, the code cell below will clone the dataset to the Google Colab’s file disk.
# This is the relative path for data if you clone the repository to a local machine
data_dir = "garbage-classification-dataset/garbage-classification-images"
try:
classes = os.listdir(data_dir)
print(classes)
except:
# This means that we are not on a local machine, so we need to clone the dataset
!git clone https://github.com/MultiX-Amsterdam/image-data-module
# Below is the path of the data on the Google Colab disk
data_dir = "/content/image-data-module/docs/garbage-classification-dataset/garbage-classification-images"
classes = os.listdir(data_dir)
print(classes)
fatal: destination path 'image-data-module' already exists and is not an empty directory.
['paper', 'glass', 'trash', 'cardboard', 'plastic', 'metal']
Transform Data#
To input the data into a machine learning algorithm, we need to transform the dataset into a normalized tensor. We can do this using PyTorch’s built-in transforms module.
from torchvision.datasets import ImageFolder
import torchvision.transforms as transforms
transformations = transforms.Compose([transforms.Resize((256, 256)), transforms.CenterCrop(224), transforms.ToTensor()])
In this example, we’re resizing the images to 256x256 pixels and cropping them to 224x224 pixels from the center. We then convert the images to tensors using transforms.ToTensor().
dataset = ImageFolder(data_dir, transform=transformations)
We then apply these transforms to the dataset using the datasets.ImageFolder class, which automatically applies the transforms to the images in the dataset:
Visualize Data#
As we build our machine learning model for image classification, it’s important to understand the data we’re working with. One way to do this is by visualizing it. By looking at the images in the dataset, we can get a sense of what features and patterns are present in them, which can inform our choice of model architecture and training strategy.
We can use a Python library like matplotlib to visualize the data by displaying sample images from the dataset along with their corresponding labels. This can help us understand the types of images in the dataset and how they are distributed across different classes.
To simplify this process, we can define a function that takes in a dataset object and displays a grid of images and their corresponding labels. This function can be called at any point during our analysis to visualize the data and better understand the images.
As we continue to build our machine learning model, we will use this function to visualize the data and its classes and gain insights that will help us improve the model.
%matplotlib inline
def show_sample(img, label):
print("Label:", dataset.classes[label], "(Class No: "+ str(label) + ")")
plt.imshow(img.permute(1, 2, 0))
img, label = dataset[2]
show_sample(img, label)
Label: cardboard (Class No: 0)

Split Data#
In order to train our deep learning model, we need to split our data into training, validation, and test sets. We set a seed for the random number generator to ensure that our data is split consistently each time we run our code. This is for reproducibility (so that the splits are the same every time when we run the code). In the code snippet below, we set the random seed to 23 and the manual seed to ensure that the split is consistent.
# Setting a seed for the random split of data:
random_seed = 23
torch.manual_seed(random_seed)
<torch._C.Generator at 0x78c7e57199f0>
Once the seed is set, we can split our dataset into training, validation, and test sets. In the code snippet below, we use PyTorch’s random_split function to split our dataset into three sets: 1593 images for training, 176 images for validation, and 758 images for testing.
# Splitting the data:
train_ds, val_ds, test_ds = random_split(dataset, [1593, 176, 758])
len(train_ds), len(val_ds), len(test_ds)
(1593, 176, 758)
Build a Dataloader#
Finally, we can load our dataset into PyTorch data loaders, which will allow us to feed the data efficiently into our machine learning model. In the code snippet below, we define data loaders for our training and validation sets, with a batch size of 32 for the training data and a batch size of 64 for the validation data. We also set the shuffle, num_workers, and pin_memory parameters to optimize the data loading process.
Keep in mind that the batch size is a hyperparameter that you can tune. However, setting the batch size to a large number may not be a good idea if your GPU and computer only have a small computer memory. Using a larger batch size consumes more computer and GPU memory.
# Loading the data
batch_size = 32
train_dl = DataLoader(train_ds, batch_size, shuffle = True, num_workers = 4, pin_memory = True)
val_dl = DataLoader(val_ds, batch_size*2, num_workers = 4, pin_memory = True)
/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py:557: UserWarning: This DataLoader will create 4 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
warnings.warn(_create_warning_msg(
Check the Dataloader#
Visualizing our data is an important step to explore the data distributions. By looking at sample images from our dataset, we can gain insights into the structure of the data and identify any issues with preprocessing or data loading.
To simplify the visualization process, we define a function called show_batch that takes in a PyTorch data loader and displays a grid of images from the batch along with their corresponding labels. This can help us identify patterns and features in the images and ensure that our data is being loaded and preprocessed correctly.
In the code snippet below, we define the show_batch function. This function takes in a data loader object and displays a grid of images from the batch along with their corresponding labels. We use the make_grid function to create a grid of images from the batch, with 16 images per row. The permute function is used to change the order of the dimensions of the tensor to match the expected input format for the imshow function.
# As before, we have a simple tool for visualization
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 6))
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(make_grid(images, nrow=8).permute(1, 2, 0))
break
show_batch(train_dl)

We have visualized our data and ensured that our data loading and preprocessing worked correctly. Now, we want to move on to creating the neural network model.
Our goal is to build a neural network that can accurately classify images into different categories. To do this, we will need to create a network architecture that is appropriate for the task. This can involve a variety of decisions, such as the number of layers in the network, the size of the filters used in convolutional layers, the activation functions used throughout the network, the learning rate, etc.
Building a neural network can be complex, but fortunately, we have powerful tools and libraries available to simplify the task. We will use PyTorch, a popular deep learning framework, to build our network.
Build the Pipeline#
In order to train and evaluate our neural network, we will need to load our pre-processed data into our model and assess its performance on our validation and test sets. To do this, we have two critical functions: data loading and model evaluation.
Data loading involves reading our pre-processed data from disk and converting it into a format that can be input into our neural network. This can involve loading images, transforming them into tensors, and creating batches for efficient processing. By properly loading our data, we can ensure that our network can process the data effectively and accurately.
On the other hand, model evaluation involves assessing our neural network’s performance on our validation and test sets. We will use a variety of metrics, such as accuracy and F1 score, to evaluate our model’s performance. This is critical for determining how well our network can classify images and whether it is ready for deployment.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
class ImageClassificationBase(nn.Module):
def accuracy(self, outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = self.accuracy(out, labels) # Calculate accuracy
return {"val_loss": loss.detach(), "val_acc": acc}
def validation_epoch_end(self, outputs):
batch_losses = [x["val_loss"] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x["val_acc"] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {"val_loss": epoch_loss.item(), "val_acc": epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch {}: train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(
epoch+1, result["train_loss"], result["val_loss"], result["val_acc"]))
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device("cuda")
else:
return torch.device("cpu")
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(), lr)
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
for batch in train_loader:
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
result["train_loss"] = torch.stack(train_losses).mean().item()
model.epoch_end(epoch, result)
history.append(result)
return history
After completing the initial data wrangling and evaluation, we are ready to move on to the exciting part of our deep learning implementation: tweaking and evaluating our neural networks.
We will work with several different neural networks based on the ResNet architecture but with some differences. Each network has been created and initialized with specific goals and objectives in mind. While some of the methods used may be exaggerated to demonstrate key concepts, it is important to keep in mind that each plays a critical role in the overall performance of our network.
During our evaluation process, we will focus primarily on accuracy as our key metric for assessing the performance of our neural networks. By analyzing their accuracy, we can determine how well they can classify images and identify areas where they may be struggling. While other metrics, such as F1 score and confusion matrices, can provide valuable insights into their performance, we will primarily focus on accuracy to streamline our evaluation process.
Throughout this process, you will be asked a series of questions about our neural networks and their performance. By fully engaging with this process, you will gain a deeper understanding of the key concepts and techniques involved in building and evaluating deep learning models. So, let us dive in and start building our networks!
As you work through our implementation, you may notice that some of the features of our neural networks are exaggerated or skewed for specific goals. For example, we may use extreme weight initialization techniques to emphasize the importance of proper weight initialization or to allow the network to display certain traits. While these features may not always be representative of real-world scenarios, they can be helpful in highlighting key concepts and techniques that are critical for success in machine learning. By understanding the reasoning behind these exaggerated features, you will be better equipped to apply these techniques in real-world situations and achieve better performance from your neural networks.
Below, you will see the network architecture for ResNet. It is interesting to see the complex detail behind recognizing features and determining their importance for a classification problem; we will use tweaked versions of this CNN. The ResNet architecture is explained in the following paper:
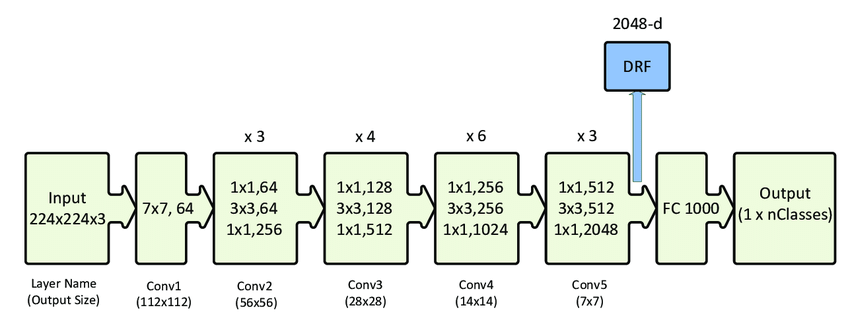
Image source – https://doi.org/10.3390/s20020447
Notice that in this tutorial, to save computational time, we will use the ResNet18 structure, a smaller version of the ResNet.
Task 3: Optimizer#
Now, let us create a basic ResNet for this task.
In the code below, we first use get_default_device() to get the default device (CPU or GPU) for training. We then initialize our ResNetGaussianWeight model and move it to the device using to_device(). Next, we move our training and validation data loaders to the device using DeviceDataLoader(). We set the number of epochs using num_epochs, and select the optimizer and learning rate using opt_func and lr, respectively. Finally, we train the model using the fit() function and store the training history in history.
It is worth noting that this is the only time we will be breaking down this specific block of code in such detail. From here on out, we will assume a basic understanding of the concepts and functions used in this code and focus on the unique features and characteristics of each neural network we explore.
Also, notice that for this assignment, we do not use the pre-trained models (by setting weights to None in models.resnet18) because we want to show differences in different weight initialization settings. In real-world applications, people often use pre-trained models.
class ResNetGaussianWeight(ImageClassificationBase):
def __init__(self):
super().__init__()
self.network = models.resnet18(weights=None)
# Replace last layer
num_ftrs = self.network.fc.in_features
self.network.fc = nn.Linear(num_ftrs, len(dataset.classes))
# Gaussian random weight initialization for all the weights
for module in self.network.modules():
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
init.normal_(module.weight, mean=0, std=0.0001)
if module.bias is not None:
init.constant_(module.bias, 0)
def forward(self, xb):
return self.network(xb)
device = get_default_device() # get the default device for training
model = ResNetGaussianWeight() # initialize the ResNet model
model = to_device(model, device) # move the model to the device (CPU or GPU)
train_dl = DeviceDataLoader(train_dl, device) # move the training data loader to the device
val_dl = DeviceDataLoader(val_dl, device) # move the validation data loader to the device
num_epochs = 10 # set the number of epochs
opt_func = torch.optim.SGD # set the optimizer
lr = 1e-4 # set the learning rate
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func) # train the model and store the training history
Epoch 1: train_loss: 1.7917, val_loss: 1.7917, val_acc: 0.2708
Epoch 2: train_loss: 1.7908, val_loss: 1.7909, val_acc: 0.2708
Epoch 3: train_loss: 1.7658, val_loss: 1.7658, val_acc: 0.2500
Epoch 4: train_loss: 1.7070, val_loss: 1.7579, val_acc: 0.1788
Epoch 5: train_loss: 1.6570, val_loss: 2.2852, val_acc: 0.2361
Epoch 6: train_loss: 1.6121, val_loss: 5.0098, val_acc: 0.2708
Epoch 7: train_loss: 1.5841, val_loss: 1.6326, val_acc: 0.3194
Epoch 8: train_loss: 1.5805, val_loss: 1.7823, val_acc: 0.3056
Epoch 9: train_loss: 1.5492, val_loss: 1.6248, val_acc: 0.3264
Epoch 10: train_loss: 1.5320, val_loss: 1.6378, val_acc: 0.4236
The code above uses the SGD (Stochastic Gradient Descent) optimizer. Now let us change the optimizer to Adam, which is explained in the following paper:
device = get_default_device() # get the default device for training
model = ResNetGaussianWeight() # initialize the ResNet model
model = to_device(model, device) # move the model to the device (CPU or GPU)
train_dl = DeviceDataLoader(train_dl, device) # move the training data loader to the device
val_dl = DeviceDataLoader(val_dl, device) # move the validation data loader to the device
num_epochs = 10 # set the number of epochs
opt_func = torch.optim.Adam # set the optimizer
lr = 1e-4 # set the learning rate
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func) # train the model and store the training history
Epoch 1: train_loss: 1.6726, val_loss: 3.1113, val_acc: 0.1788
Epoch 2: train_loss: 1.5570, val_loss: 2.1502, val_acc: 0.2222
Epoch 3: train_loss: 1.5363, val_loss: 1.6092, val_acc: 0.3472
Epoch 4: train_loss: 1.5040, val_loss: 2.5672, val_acc: 0.2326
Epoch 5: train_loss: 1.4677, val_loss: 1.2545, val_acc: 0.4948
Epoch 6: train_loss: 1.4529, val_loss: 1.4490, val_acc: 0.3924
Epoch 7: train_loss: 1.3804, val_loss: 1.6971, val_acc: 0.3490
Epoch 8: train_loss: 1.3542, val_loss: 1.6390, val_acc: 0.3872
Epoch 9: train_loss: 1.3132, val_loss: 1.6851, val_acc: 0.4392
Epoch 10: train_loss: 1.2259, val_loss: 1.4424, val_acc: 0.4497
Assignment 3#
In this task, we used two different optimizers while keeping all other settings and hyperparameters the same. What do you observe for the evaluation results? What are the differences?
YOUR ANSWER HERE
Task 4: Learning Rate#
Continue Task 3, now let us keep using the SGD optimizer while lowering the learning rate.
device = get_default_device() # get the default device for training
model = ResNetGaussianWeight() # initialize the ResNet model
model = to_device(model, device) # move the model to the device (CPU or GPU)
train_dl = DeviceDataLoader(train_dl, device) # move the training data loader to the device
val_dl = DeviceDataLoader(val_dl, device) # move the validation data loader to the device
num_epochs = 10 # set the number of epochs
opt_func = torch.optim.SGD # set the optimizer
lr = 1e-8 # set the learning rate
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func) # train the model and store the training history
Epoch 1: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1441
Epoch 2: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1493
Epoch 3: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1181
Epoch 4: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1372
Epoch 5: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1389
Epoch 6: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1302
Epoch 7: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1372
Epoch 8: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1372
Epoch 9: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1319
Epoch 10: train_loss: 1.7918, val_loss: 1.7918, val_acc: 0.1198
Now let us increase the learning rate to a large number and still keep using the SGD optimizer.
device = get_default_device() # get the default device for training
model = ResNetGaussianWeight() # initialize the ResNet model
model = to_device(model, device) # move the model to the device (CPU or GPU)
train_dl = DeviceDataLoader(train_dl, device) # move the training data loader to the device
val_dl = DeviceDataLoader(val_dl, device) # move the validation data loader to the device
num_epochs = 10 # set the number of epochs
opt_func = torch.optim.SGD # set the optimizer
lr = 12 # set the learning rate
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func) # train the model and store the training history
Epoch 1: train_loss: 503743414272.0000, val_loss: 575321808044032.0000, val_acc: 0.1493
Epoch 2: train_loss: 2375276.5000, val_loss: 3.1059, val_acc: 0.1788
Epoch 3: train_loss: 182368624.0000, val_loss: 2.5338, val_acc: 0.1441
Epoch 4: train_loss: 295.1201, val_loss: 19.2769, val_acc: 0.1441
Epoch 5: train_loss: 2444.5940, val_loss: 2.2590, val_acc: 0.1441
Epoch 6: train_loss: 1807.6530, val_loss: 2.7169, val_acc: 0.1441
Epoch 7: train_loss: 2.9107, val_loss: 2.6840, val_acc: 0.1441
Epoch 8: train_loss: 2.6635, val_loss: 1962573.8750, val_acc: 0.1493
Epoch 9: train_loss: 2.7044, val_loss: 14624171.0000, val_acc: 0.1788
Epoch 10: train_loss: 4.2750, val_loss: 2.7830, val_acc: 0.1441
Assignment 4#
In this task, we used two different learning rates while keeping all other settings and hyperparameters the same. What do you observe for the evaluation results? What are the differences of these results when compared to the SGD optimizer version in Task 3?
YOUR ANSWER HERE
Task 5: Weight Initiation#
Next, let us initialize all the model weights to zero. We still keep using the SGD optimizer and keep the learning rate the same as the one used in Task 3.
class ResNetZeroWeight(ImageClassificationBase):
def __init__(self):
super().__init__()
self.network = models.resnet18(weights=None)
# Replace last layer
num_ftrs = self.network.fc.in_features
self.network.fc = nn.Linear(num_ftrs, len(dataset.classes))
# Zero weight initialization for all the weights
for module in self.network.modules():
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
init.zeros_(module.weight)
if module.bias is not None:
init.zeros_(module.bias)
def forward(self, xb):
return self.network(xb)
device = get_default_device() # get the default device for training
model = ResNetZeroWeight() # initialize the ResNet model
model = to_device(model, device) # move the model to the device (CPU or GPU)
train_dl = DeviceDataLoader(train_dl, device) # move the training data loader to the device
val_dl = DeviceDataLoader(val_dl, device) # move the validation data loader to the device
num_epochs = 10 # set the number of epochs
opt_func = torch.optim.SGD # set the optimizer
lr = 1e-4 # set the learning rate
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func) # train the model and store the training history
Epoch 1: train_loss: 1.7917, val_loss: 1.7917, val_acc: 0.2708
Epoch 2: train_loss: 1.7916, val_loss: 1.7916, val_acc: 0.2708
Epoch 3: train_loss: 1.7915, val_loss: 1.7915, val_acc: 0.2708
Epoch 4: train_loss: 1.7914, val_loss: 1.7914, val_acc: 0.2708
Epoch 5: train_loss: 1.7914, val_loss: 1.7913, val_acc: 0.2708
Epoch 6: train_loss: 1.7913, val_loss: 1.7912, val_acc: 0.2708
Epoch 7: train_loss: 1.7912, val_loss: 1.7911, val_acc: 0.2708
Epoch 8: train_loss: 1.7911, val_loss: 1.7910, val_acc: 0.2708
Epoch 9: train_loss: 1.7910, val_loss: 1.7909, val_acc: 0.2708
Epoch 10: train_loss: 1.7909, val_loss: 1.7908, val_acc: 0.2708
Besides the Gaussian weight initialization that we used in the previous task, we can also use uniform weight initialization. The method is documented in the following paper and has been used widely.
In the following code, we change only the weight initialization. We still keep using the SGD optimizer and keep the learning rate the same as the one used in Task 3.
class ResNetUniformWeight(ImageClassificationBase):
def __init__(self):
super().__init__()
self.network = models.resnet18(weights=None)
# Replace last layer
num_ftrs = self.network.fc.in_features
self.network.fc = nn.Linear(num_ftrs, len(dataset.classes))
# Kaiming initialization for all the weights
for module in self.network.modules():
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
init.kaiming_uniform_(module.weight)
if module.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(module.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(module.bias, -bound, bound)
def forward(self, xb):
return self.network(xb)
device = get_default_device() # get the default device for training
model = ResNetUniformWeight() # initialize the ResNet model
model = to_device(model, device) # move the model to the device (CPU or GPU)
train_dl = DeviceDataLoader(train_dl, device) # move the training data loader to the device
val_dl = DeviceDataLoader(val_dl, device) # move the validation data loader to the device
num_epochs = 10 # set the number of epochs
opt_func = torch.optim.SGD # set the optimizer
lr = 1e-4 # set the learning rate
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func) # train the model and store the training history
Epoch 1: train_loss: 2.5672, val_loss: 2.4399, val_acc: 0.1267
Epoch 2: train_loss: 2.2206, val_loss: 2.1561, val_acc: 0.1493
Epoch 3: train_loss: 1.9698, val_loss: 1.9118, val_acc: 0.1823
Epoch 4: train_loss: 1.8171, val_loss: 1.7625, val_acc: 0.2413
Epoch 5: train_loss: 1.7176, val_loss: 1.6746, val_acc: 0.3229
Epoch 6: train_loss: 1.6545, val_loss: 1.6114, val_acc: 0.3524
Epoch 7: train_loss: 1.6066, val_loss: 1.5637, val_acc: 0.3889
Epoch 8: train_loss: 1.5805, val_loss: 1.5230, val_acc: 0.3941
Epoch 9: train_loss: 1.5565, val_loss: 1.4921, val_acc: 0.4427
Epoch 10: train_loss: 1.5284, val_loss: 1.4607, val_acc: 0.4601
Assignment 5#
This task shows you two other different ways of initializing the model weights (i.e., the model parameters). What do you observe for the evaluation results? What are the differences of these results when compared to the SGD optimizer version in Task 3?
YOUR ANSWER HERE
Task 6: Model explanations#
In this task, we will qualitatively analyze the model performance by visualizing which images are predicted as each class and their GradCAMs. This can help us understand where the model is failing. The code below does the task for us.
def scale_to_01(arr):
"""
Scales an array so all its values lie in the interval [0, 1].
Parameters
----------
arr : numpy.array
The original array.
Returns
-------
numpy.array
The sclaed array.
"""
min_val = arr.min()
max_val = arr.max()
scaled_array = (arr - min_val) / (max_val - min_val)
return scaled_array
def display_grad_cam(model, target_layers, images):
"""
Computes and displays the GradCAM for a convolutional neural network for a
batch of images.
Parameters
----------
model : nn.Module
Model on which we want to compute the GradCAM.
target_layers : List[nn.Module]
List of convolutional layers where the GradCAM is computed. If a list
with several layers is provided, the CAM will be averaged accross them.
images: torch.Tensor
Batch of images for which the GradCAM shall be computed.
"""
# Apply GradCAM to the images
grad_cam = GradCAM(model=model, target_layers=target_layers)
cams = grad_cam(input_tensor=images, targets=None, aug_smooth=True, eigen_smooth=True)
# Convert images to numpy arrays and scale them to [0,1]. This step is
# necessary for the show_cam_on_image funciton to work
images = scale_to_01(np.array(images.permute(0, 2, 3, 1).cpu()))
# Merge each image with its cam
cam_images = []
for image, cam in zip(images, cams):
cam_images.append(show_cam_on_image(image, cam, use_rgb=True, image_weight=0.75))
cam_images = torch.tensor(np.array(cam_images))
# Display grid with cams of all images in the batch
nrow = 6
img_size_factor = 1.5
grid_image = utils.make_grid(cam_images.permute(0, 3, 1, 2), nrow=nrow).permute(1, 2, 0)
plt.figure(figsize=(nrow*img_size_factor, ((images.shape[0]/nrow)+1)*img_size_factor))
plt.title("Model: " + model.__class__.__name__)
plt.axis("off")
plt.imshow(grid_image, vmin=0, vmax=1)
plt.show()
# Get a batch of (64) images and compute their predicted labels
images, _ = next(iter(val_dl))
images = images[0:64]
predicted_labels = torch.argmax(model(images), dim=1)
# Divide the batch per predicted class
class_images = {label: [] for label in set([label.item() for label in predicted_labels])}
for i in range(len(predicted_labels)):
label = predicted_labels[i].item()
class_images[label].append(images[i])
# Compute GradCAM for samples of each class
for label, images in class_images.items():
print("\nPredicted Label: " + dataset.classes[label])
images_tensor = torch.stack(images)
display_grad_cam(model, [model.network.layer4[1].conv2], images_tensor)
Predicted Label: cardboard

Predicted Label: glass

Predicted Label: metal

Predicted Label: paper
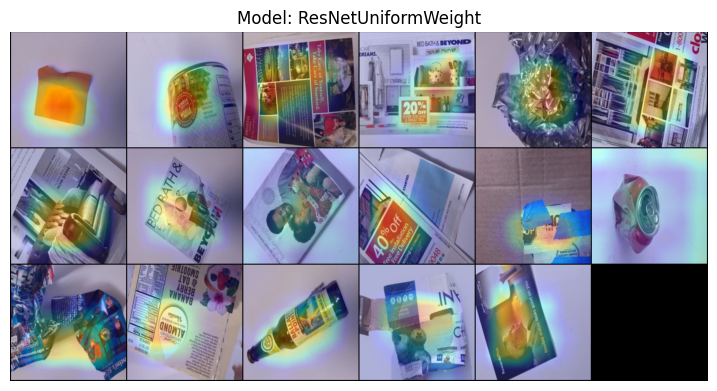
Predicted Label: plastic

Assignment 6#
What do you observe in the gradCAMs for the different classes? What does the model pay attention to for each class? Can you spot any patterns in the errors made by the model?
YOUR ANSWER HERE
Task 7: Experiments (optional)#
Now, given all of this, it is up to you to analyse these algorithms, the outcomes, and determine the variables which contribute more; the Gemeente is relying on you for the future, so do your best to understand and advise based on this.
Assignment 7 (optional)#
Conduct experiments and write a short paragraph to recommend the best CNN, optimizer, and learning rate (of the ones used) for the Gemeente to carry forward in their development of a full pipeline AI garbage classifier. You can try different network architecture, number of epochs, learning rate, and weight initializations.
YOUR ANSWER HERE
Task 8: Theory Questions#
Assignment 8.1: Role of the Last Layer#
We modified the ResNet architecture to replace only the last layer for our task. The rest of the neural net remains the same as we imported the network. What is the purpose of changing the last layer of the network?
YOUR ANSWER HERE
Assignment 8.2: Constant Weight Initialization#
As you saw in Task 5, if we were not to randomize the model weights and instead initialize the weights to a constant value (or simply zero), we would encounter a famous problem of Deep Learning. Research online to discover what we call this issue, why it happens, and why randomly initializing the weights fixes this issue.
YOUR ANSWER HERE
Assignment 8.3: Weight Initialization Comparison#
There are different types of weight initializations. You saw Zero, Gaussian Distributed, and Kaiming methods here. Research these methods, and try to explain briefly in your own words the strengths and weaknesses of each.
YOUR ANSWER HERE
Assignment 8.4: Network Complexity#
You might think that a Deep Neural Network is always better. But as you saw in the tutorial, sometimes adding more layers to increase the complexity of neural networks may not really help. There is a name for the phenomenon of adding too much complexity, which may (or may not) make the performance worse. Find out what it is called and briefly describe why it happens and how to fix it if the architecture is to remain mostly the same.
YOUR ANSWER HERE
Assignment 8.5: Learning Rate#
In Task 4, we used very low and high learning rates. This is a classic problem in Deep Learning. Identify what arises when we do this, and give your best resolutions to these issues (some of which we used).
YOUR ANSWER HERE
Assignment 8.6: Vanishing Gradient#
Although we did not show you here, neural networks can suffer from Vanishing Gradient. An example of vanishing gradient can be found in this notebook. Mathematically it is because in the back-propagation stage, the gradient of the loss function compared to the weights is too small (here is more explaination). They cannot update the weights enough to make meaningful changes. There are many ways to fix these issues. Try to list as many of them as possible, and using the above information and your own further research, try to convey why these fix the issue.
YOUR ANSWER HERE
- 1
Credit: this teaching material is created by Bryan Fleming and revised by Alejandro Monroy under the supervision of Yen-Chia Hsu.